partition和shard的区别
partition和shard在不同的中间件中的概念或多或少略有区别,我们这里只关注这两个概念在clickhouse中的语义:
分区partition
表中的数据可以按照指定的字段分区存储,每个分区在文件系统中都是都以目录的形式存在。常用时间字段作为分区字段,数据量大的表可以按照小时分区,数据量小的表可以在按照天分区或者月分区,查询时,使用分区字段作为Where条件,可以有效的过滤掉大量非结果集数据。
- 创建分区的方法比较简单,只需要在建表时通过partition by语法指定即可;
- 不止可以按某个字段做partition by,还可以支持按任意合法的表达式进行分区操作,比如toYYYYMM()按月做分区;
- 支持对partition进行TTL管理,淘汰过期的分区数据;
- 插入数据到分区表中时,先会将数据写入到分区目录下的segment文件中,后台程序会自动进行合并,当然也可以通过optimize命令手动触发合并。
分片shard
分片则只有在分布式下存在, 一个分片则是一个clickhouse实例,将全量数据水平切分到多个clickhouse实例中提高查询性能。
副本
clickhouse的副本同步机制是通过Zookeeper来完成的,包括主副本选举、副本状态感知、操作日志分发、任务队列和BlockID去重判断等。在执行INSERT数据写入、MERGE分区和MUTATION操作的时候,都会涉及与ZooKeeper的通信。但是在通信的过程中,并不会涉及任何表数据的传输,在查询数据的时候也不会访问ZooKeeper,所以不必过于担心ZooKeeper的承载压力。所以我们想使用副本功能必须部署Zookeeper,目前最新的版本clickhouse已经实现了自己的协调器(clickhouse keeper),zk的替代品,我们后面再讨论。
原理
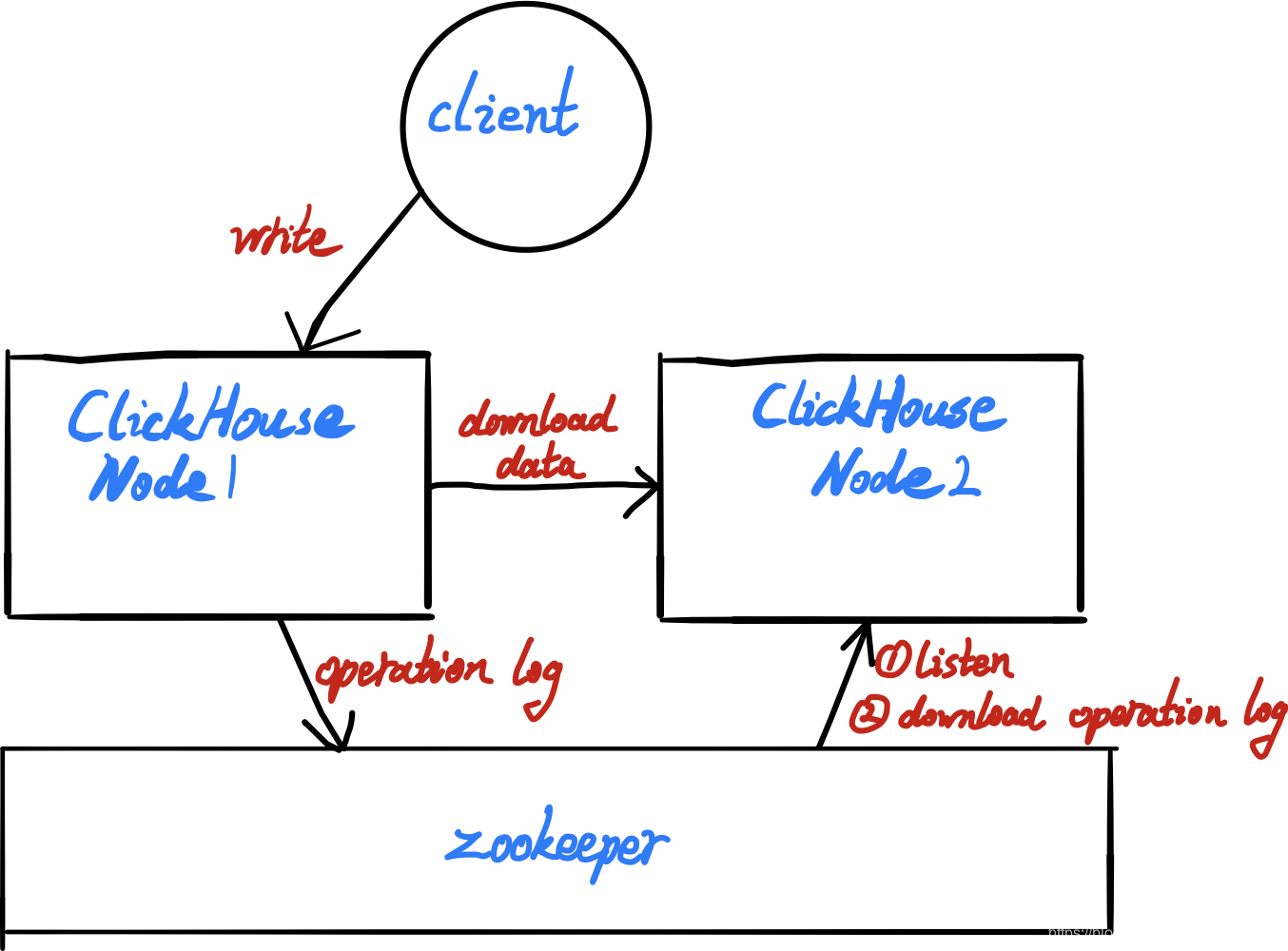
大致的原理就是多个节点会在zk中为同一个表配置同一个path,或者说zk的语境中是同一个节点。当某个节点写入操作日志后,另一个节点watch到zk这个事件后,立即去zk拉取操作日志,然后根据操作日志到对应节点拉取数据。
实践
我这里就单机docker 3节点配置了。
首先创建独立的docker network,因为clickhouse默认会使用其主机名注册到zk中,对应docker的主机名如果不在同一个docker network中,是无法通过容器主机名互访的。
1 | docker network create clickhouse |
docker启动Zookeeper
1 | docker run -d --net clickhouse -p 2181:2181 rishabh208/zookeeper:latest |
注意,官方镜像较新,不适合clickhouse,这里使用这个3.4的镜像。
docker启动三个节点的clickhouse
startup.sh
1 |
|
这里启动了三个节点,分别将容器8123映射到主机的8124,8125,8126,将容器9000映射到主机。
其中 config1 config2 config3 中把clickhouse默认的几个配置放进去
1 | (base) fenix@fenixs:~/clickhouse$ ls config1/clickhouse-server/ |
其中config.xml 下添加如下配置
1 | <zookeeper incl="zookeeper-servers" optional="true" /> |
listen_host改为:
1 | <listen_host>0.0.0.0</listen_host> |
metrica.xml中添加
1 | <yandex> |
然后执行sh startup.sh
在上面的脚本启动的3个节点中,并没有配置任何集群相关的信息,换句话说三个节点除了连接了同一个zk外,是毫无关系的三个独立clickhouse实例。
配置
在使用副本时,不需要依赖任何集群配置。ReplicatedMergeTree结合ZooKeeper就能完成全部工作。
其语法为:
1 | ENGINE = ReplicatedMergeTree('zk_path', 'replica_name') |
其中zk_path 指定zk中表的路径,replica_name 表明副本的名称。
zkpath并没有固定规则,只要能唯一定位一个分片即可,不过有一些约定俗成的模板。
/clickhouse/tables/{shard}/table_name
这里面指定shard分片,table_name表名。replica_name 中指定副本的名称。
1 | ReplicatedMergeTree('/clickhouse/tables/01/test_1, '01') |
测试
在节点A上创建表
1 | CREATE TABLE replicated_sales_1 ( |
在节点B上创建表
1 | CREATE TABLE replicated_sales_1 ( |
在节点A上写入表
1 | insert into replicated_sales_1 values ('A222',123123,now()); |
在B节点可以正常看到数据
1 | select * from replicated_sales_1; |
集群
clickhouse的集群并不是某种类似其他中间件的节点级别的全局的,固定的集群关系。clickhouse能够根据可用性,数据分片,性能的需求,自由组合现有节点成为一个集群,这种集群关系可以是局部的。
比如我们的业务中某些表需要更好的读性能,高可用可以选择其中一部分节点创建多副本集群;另一部分业务表数据量巨大,需要水平切片的,则可以选择一部分节点创建分片集群;也可以创建既分片又副本的集群,总之我们可以任意定义一个集群。这些定义的集群之间的节点可以重叠可以不重叠,只需要保证集群内的节点不重叠即可。
比如我们配置2节点2副本的集群:
1 | <ck_2s_2r> |
共4个节点,查看我们创建的集群:
1 | select * from system.clusters; |
ON CLUSTER语法
1 | CREATE/DROP/RENAME/ALTER TABLE ON CLUSTER cluster_name |
可以在集群上所有的节点建表
比如我们可以在每个节点上创建一个MergeTree
1 | create table test_001 on cluster ck_2s_2r (id String,date DateTime) engine MergeTree order by id; |
然后就在集群上每个节点创建一个MergeTree,本质上跟你手动在每个节点上执行create table 创建MergeTree是同样的效果。
同样我们可以在集群中创建
1 | CREATE TABLE test_003 ON CLUSTER ck_2s_2r |
注意这里需要我们在每个节点的metrica.xml 中配置宏
1 | <macros> |
使用宏来指定zkpath是和我们前面集群定义的分片没有关系的,如果想用上我们前面配置的集群分片和副本。可以这样:
把database创建到对应集群上
1 | create database ck_2s_2r on cluster ck_2s_2r; |
然后就可以直接免配置zkpath创建ReplicatedMergeTree了
1 | CREATE TABLE ck_2s_2r.test_001 ON CLUSTER ck_2s_2r |
此时我们ck1 和 ck2 互为副本,ck3 和 ck4互为副本,我们给1插数据2会同步,给3插数据4会同步。
分布式表
到目前为止,我们的2s2r分片副本表还是本地表,链接1节点无法看到3节点的数据。这里我们可以创建分布式表,为我们的分片副本表创建一个视图。
规则如下
1 | ENGINE = Distributed(cluster, database, table [,sharding_key]) |
这里table是对应要代理的本地表
我们创建:
1 | create table ck_2s_2r.test_001_all on cluster ck_2s_2r (id String,date DateTime) engine Distributed ('ck_2s_2r','ck_2s_2r','test_001',rand()); |
到on cluster上,意味着集群所有节点都能访问到分布式表。
分布式表支持insert select
1 | aad19fa35aa0 :) insert into ck_2s_2r.test_001_all values ('3A',now()),('4B',now()),('5C',now()); |
1 | aad19fa35aa0 :) SELECT * |
分布式表的原理
查询节点接受到Distributed表的select查询后,会将其转换为对每个子节点的查询,然后向每个子节点发起查询,然后汇总结果。
环形复制
clickhouse原生并不支持环型复制(Circular Replication),所谓环形复制就是:比如在3个节点上实现3分片2副本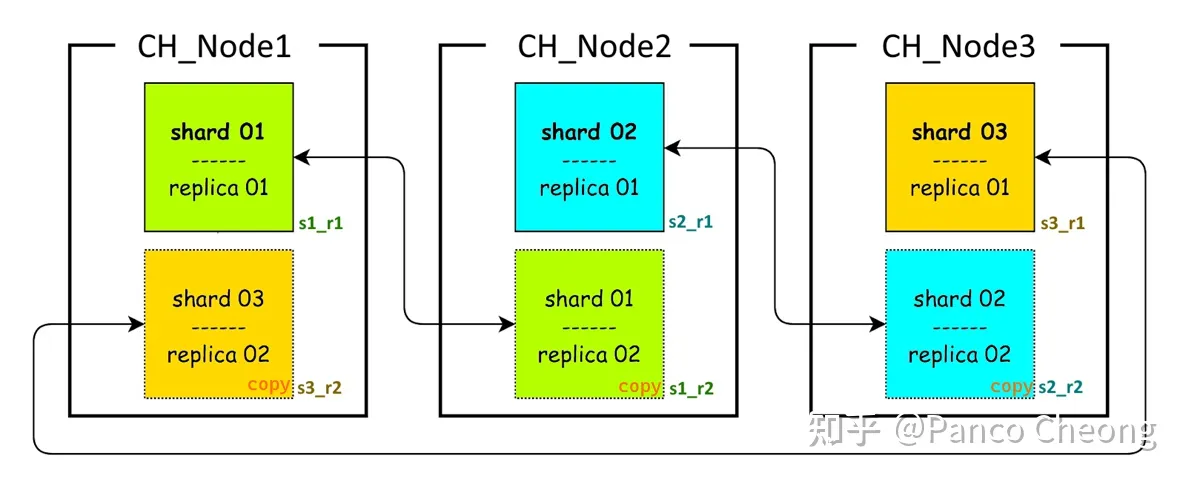
这种拓扑结构每个节点保存2个shard————即2/3的数据,并且能容忍1个节点离线。
对于原生clickhouse 集群如果想实现3分片2副本则至少需要6个节点,但是有一些hack方式可以解决这个问题。
https://github.com/ClickHouse/ClickHouse/issues/7611
这里可以看到den-crane并不推荐环形复制,“Personally I don’t recommend this schema because second replicas kill performance (they use cache / I/O/ CPU).” 这种方式会对性能造成影响,clickhouse并未对这种拓扑做优化,某些情况下会导致查询本应分摊到多个节点的计算落到同一节点。
知乎这里有个博主写的使用default_database的方案实现环形复制。
https://zhuanlan.zhihu.com/p/461792873
他的这个方案中的模式使用default_database来区分同一个节点上的两个分片,但是这种方式需要手动指定zk_path 而不能更为智能的使用on cluster语法。
对于生产环境部署,使用每节点一分片,节点数等于分片数乘副本数更为可靠。