介绍 calico也是一种非常流行的CNI实现。https://github.com/projectcalico/calico
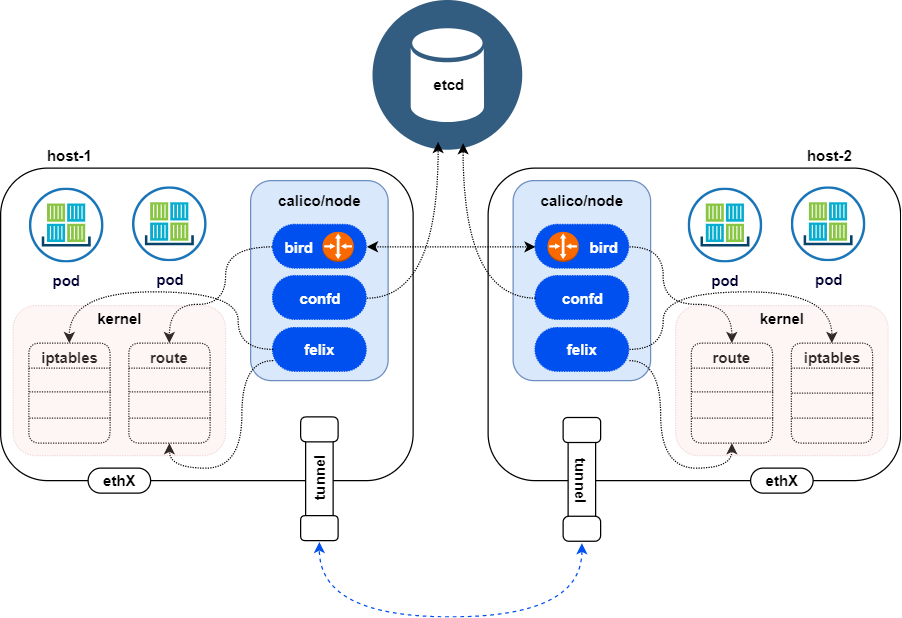
架构图
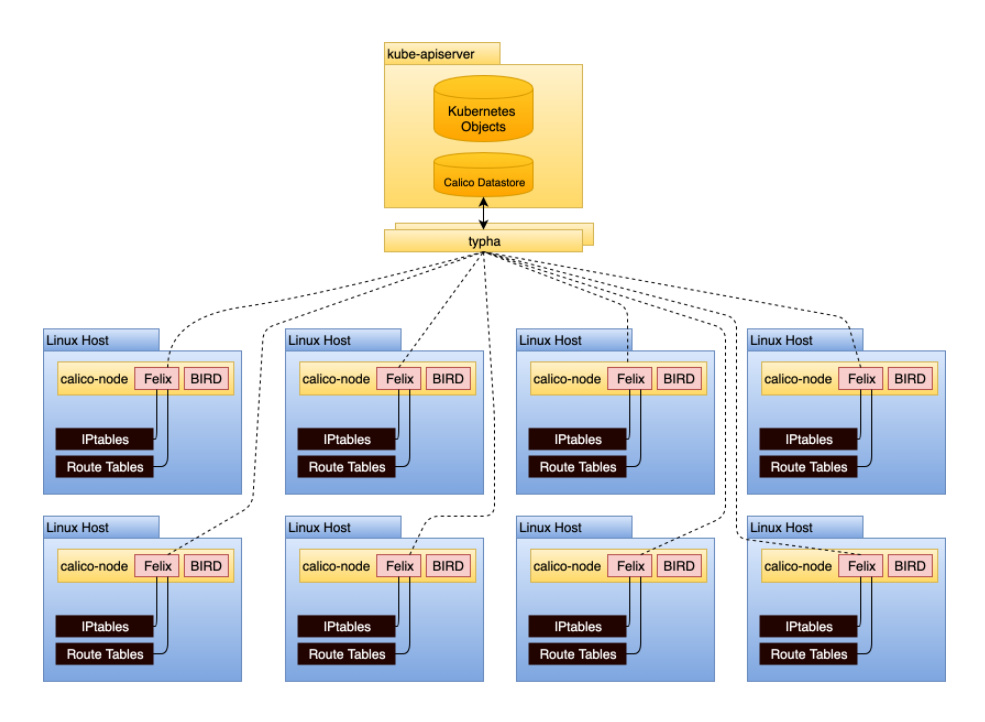
存储后端 这个图比较老,目前新版的架构中,calico在存储方面还支持一个中间层Typha。存储后端上支持三种:
etcd
CRD
Typha
对于小规模集群,使用1,2方式就可以了,对于大规模集群使用前两种方案会对etcd带来较大压力。官方推荐使用Typha。
Typha自身维护一个对存储的链接就可以了,避免大量节点的felix对k8s Apiserver,etcd造成巨大压力。
路由后端 calico_backend bird/vxlan
bird 即BGP
vxlan calico也支持这种方式在一些不支持ipip的常见下部署overlay网络。
BGP下的传输后端
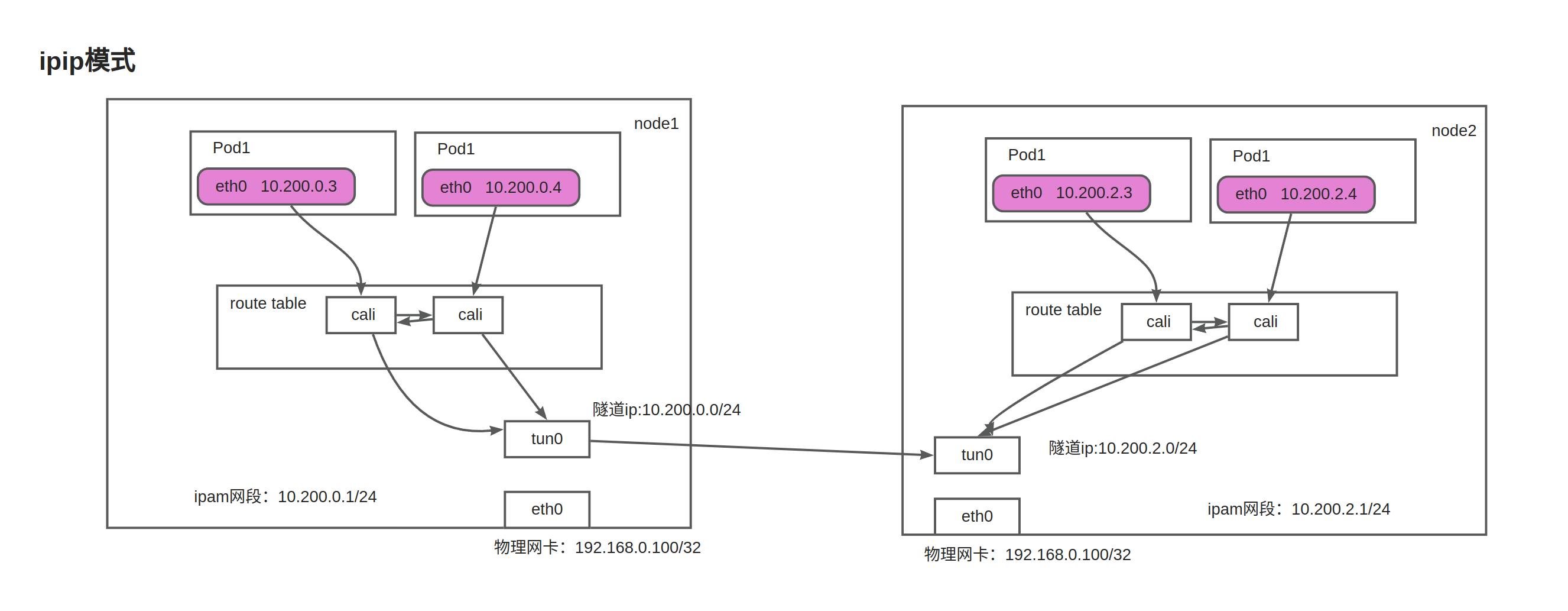
ipip模式 即ip in ip模式,有封装和解封装的损耗,可以跨子网。
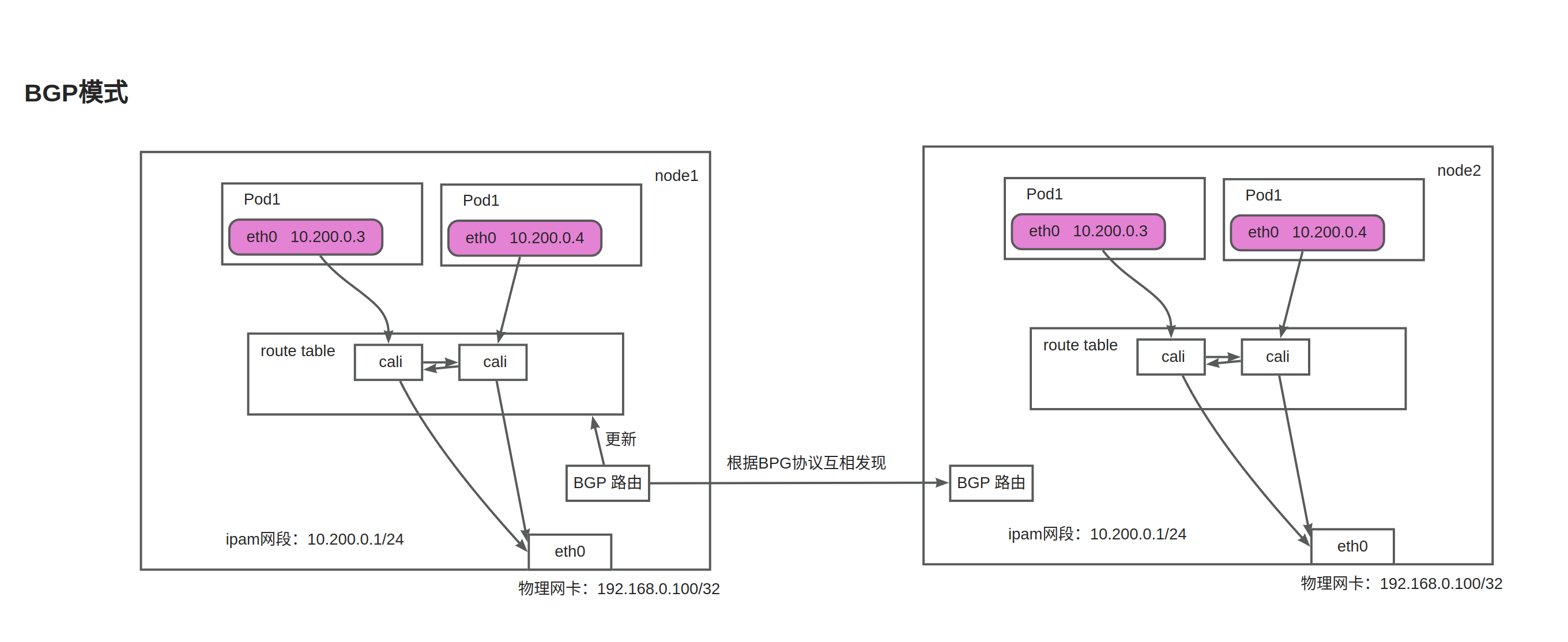
BGP模式 没有封装的损耗,配合BGP反射,可以支撑超大规模的集群。
节点 每个节点将会安装calico-node,其中包含两个进程:
Felix:calico的核心组件,运行在每个节点上。主要的功能有接口管理、路由规则、ACL规则和状态报告
接口管理:Felix为内核编写一些接口信息,以便让内核能正确的处理主机endpoint的流量。特别是主机之间的ARP请求和处理ip转发。
路由规则:Felix负责主机之间路由信息写到linux内核的FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。
ACL规则:Felix负责将ACL策略写入到linux内核中,保证主机endpoint的为有效流量不能绕过calico的安全措施。
状态报告:Felix负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入etcd,使其对网络的其他组件和操作人员可见。
BIRD :BGP客户端,Calico在每个节点上的都会部署一个BGP客户端,它的作用是将Felix的路由信息读入内核,并通过BGP协议在集群中分发。
Calico-Controller Calico-Controller的主要作用为,负责识别Kubernetes对象中影响路由的变化。比如新建Pod和新增节点都需要Calico参与相关网络配置。这里需要Controller watch到对应的event后将变更保存到calico自己IDE存储中。并通知到对应的组件。
部署 对于测试学习场景,我们直接部署默认配置就可以了。
1 kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
默认情况下,calico使用的是ipip隧道模式
1 2 3 2021-10-02 05:04:26.657 [INFO][9] startup/startup.go 651: CALICO_IPV4POOL_NAT_OUTGOING is true (defaulted) through environment variable 2021-10-02 05:04:26.657 [INFO][9] startup/startup.go 992: Ensure default IPv4 pool is created. IPIP mode: Always, VXLAN mode: Never 2021-10-02 05:04:26.718 [INFO][9] startup/startup.go 1002: Created default IPv4 pool (10.244.0.0/16) with NAT outgoing true. IPIP mode: Always, VXLAN mode: Never
生产部署 对于生产部署官方的建议是:
安装 Typha 以确保数据存储可扩展性。
对单个子网集群不使用封装。
对于多子网集群,在 CrossSubnet 模式下使用 IP-in-IP。
根据网络 MTU 和选择的路由模式配置 Calico MTU。
为能够增长到 50 个以上节点的集群添加全局路由反射器。
ipip模式
节点上看到的路由信息
1 2 3 4 5 6 7 8 9 10 11 12 13 [root@node3 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.31.1 0.0.0.0 UG 100 0 0 enp0s3 10.233.90.0 192.168.31.170 255.255.255.0 UG 0 0 0 tunl0 10.233.92.0 0.0.0.0 255.255.255.0 U 0 0 0 * 10.233.92.3 0.0.0.0 255.255.255.255 UH 0 0 0 calib8bf7d77053 10.233.92.4 0.0.0.0 255.255.255.255 UH 0 0 0 cali57c3e1bd0c7 10.233.92.5 0.0.0.0 255.255.255.255 UH 0 0 0 cali48737a02ab9 10.233.96.0 192.168.31.171 255.255.255.0 UG 0 0 0 tunl0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.168.31.0 0.0.0.0 255.255.255.0 U 100 0 0 enp0s3
node3的节点ip为192.168.31.172,cni网段为10.233.92.0/24。
1 2 3 4 5 6 7 8 9 10 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 3: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue link/ether 1a:99:14:82:20:14 brd ff:ff:ff:ff:ff:ff inet 10.233.92.4/32 scope global eth0 valid_lft forever preferred_lft forever 4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0
路由全部走eth0
1 2 3 4 5 # route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0 169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
如果是10.233.92.0/24中其他ip不在本地的,则会走到blackhole 10.233.92.0/24 proto bird 这条黑洞规则。
同节点访问 从前面的路由表看,同节点访问会直接路由到对应的calixxxx设备。
跨节点访问流程
容器中的网卡用的是veth的pair虚拟网卡,一端连接到容器,另一端连着宿主机。
容器中的报文通过calixxx到达宿主机。然后根据宿主机的路由,报文发往tunl0设备。
报文到达tunl0时,会再次封装一层ip报文头,把目标node的ip作为目的ip,然后通过宿主网卡机将报文发出。
对端node收到报文后,解开外层ip报文头,发现是ipip报文,会转交给tunl0
tunl0查找路由,就发送给calixxxxxx,对端容器就收到了报文。
BGP模式 bgp工作模式和flannel的host-gw模式非常类似;
1 2 3 4 - name: CALICO_IPV4POOL_IPIP value: "Never" - name: CALICO_IPV4POOL_VXLAN value: "Never"
arp代理 Calico在BGP模式下使用了 ARP代理(ARP proxy)的方式解决了 ARP广播域的问题,实现了跨节点的通信。在ARP代理模式下,每个节点上都有一个 ARP代理,节点之间不再进行 ARP广播,而是由 ARP代理响应 ARP请求。
在 ARP代理模式下,节点A发送ARP请求时,ARP请求会被拦截并转发到目标节点所在的节点B,节点B的 ARP代理会响应 ARP请求,将自己的 MAC地址返回给节点A。节点A收到节点B的 MAC地址后,就可以向节点B发送数据了。
需要注意的是,ARP代理模式只适用于同一个网络内的节点通信,如果两个节点在不同的网络内,则需要使用其他方式,如路由器进行通信。
1 2 3 [13:39:56 root@node-3 ~]#cat /proc/sys/net/ipv4/conf/cali385152345a1/proxy_arp 1 #proxy_arp代理是启用状态 #容器在没有任何网络请求时查看arp
BGP原理
路由反射器RR(Route Reflector):允许把从IBGP对等体学到的路由反射到其他IBGP对等体的BGP设备,类似OSPF网络中的DR。
客户机(Client):与RR形成反射邻居关系的IBGP设备。在AS内部客户机只需要与RR直连。
非客户机(Non-Client):既不是RR也不是客户机的IBGP设备。在AS内部非客户机与RR之间,以及所有的非客户机之间仍然必须建立全连接关系。
始发者(Originator):在AS内部始发路由的设备。Originator_ID属性用于防止集群内产生路由环路。
集群(Cluster):路由反射器及其客户机的集合。Cluster_List属性用于防止集群间产生路由环路。
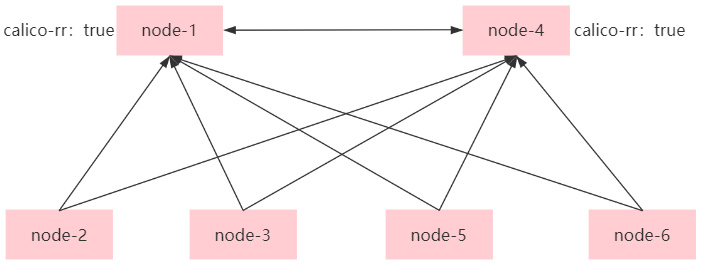
calico的BGP calico的IPIP与不使用封装会使用到BGP进行组网,保证不同node节点的Pod互相通信,默认情况下calico所有的node节点都是以对等方式进行BGP的互相连接,如果集群node节点数量大于50以上这种方式会造成每个节点的BGP连接指数级增多,所以需要引入BGP RR 即路由反射器。即一部分node与RR进行对等连接之后RR之间在进行对等连接,以减少默认模式下的node全对等连接。如果集群规模超过200个节点需要配置实际的底层网络集成BGP进行相关配置。
配置BGP Peer
1 2 3 4 5 6 7 8 9 10 [17:06:18 root@node-1 ~]#cat BGPPeer-rr.yml apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: rr-to-node spec: # 规则1:普通 bgp node 与 rr 建立连接 nodeSelector: "!has(calico-rr)" peerSelector: has(calico-rr)
1 2 3 4 5 6 7 8 9 --- apiVersion: projectcalico.org/v3 kind: BGPPeer metadata: name: rr-to-rr spec: # 规则2:route reflectors 之间也建立连接 nodeSelector: has(calico-rr) peerSelector: has(calico-rr)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #应用 [17:15:41 root@node-1 ~]#calicoctl apply -f BGPPeer-rr.yml #之后需要导出node1与node4的配置,进行修改 [17:17:09 root@node-1 ~]#calicoctl get node 192.168.10.11 -oyaml --export >11.yml spec: bgp: ipv4Address: 192.168.10.11/24 ipv4IPIPTunnelAddr: 172.20.36.128 routeReflectorClusterID: 224.0.0.1 #要充当路由反射器的每个节点都必须有一个集群ID,通常是一个未使用的IPv4地址,如果多个路由反射器是高可用的他们的集群id应该一致,用于冗余和防环 orchRefs: - nodeName: 192.168.10.11 orchestrator: k8s status: podCIDRs: - "" - 172.20.4.0/24 #给node1与node4节点打标签 [17:22:59 root@node-1 ~]#kubectl label nodes 192.168.10.11 calico-rr=true [17:22:59 root@node-1 ~]#kubectl label nodes 192.168.10.14 calico-rr=true #之后在node2查看node对等状态 [17:14:51 root@node-2 ~]#calicoctl node status Calico process is running. IPv4 BGP status +---------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------+---------------+-------+----------+-------------+ | 192.168.10.11 | node specific | up | 09:14:47 | Established | #这里可以看到node2与node1和node4为对等状态 | 192.168.10.14 | node specific | up | 09:23:12 | Established | +---------------+---------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. #在node1或node4查看 [17:23:11 root@node-1 ~]#calicoctl node status Calico process is running. IPv4 BGP status +---------------+---------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------+---------------+-------+----------+-------------+ | 192.168.10.12 | node specific | up | 09:14:48 | Established | #node1和node4与没有calico-rr=true的节点都建立了对等连接 | 192.168.10.13 | node specific | up | 09:14:48 | Established | | 192.168.10.15 | node specific | up | 09:14:50 | Established | | 192.168.10.16 | node specific | up | 09:14:48 | Established | | 192.168.10.14 | node specific | up | 09:23:02 | Established | +---------------+---------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found.