一致吗?
为什么说Zookeeper中写是强一致的,这是因为Zookeeper任何写操作都发生在leader节点,所有写操作管你并发不并发一律串行。换句话说整个Zookeeper集群有且仅有一个修改整个集群的状态的入口,那就是leader节点。即使发生脑裂(逻辑上分成2 leader)也必须选举完成,分裂的两个集群内部对各自的leader都打成共识后,两个集群又各自保持一个leader写入。因此我们可以说,对集群状态的写入,始终是线性的,串行的,强一致的。
但是读呢?Zookeeper中的读有时可能会跟我们的期望不一致:
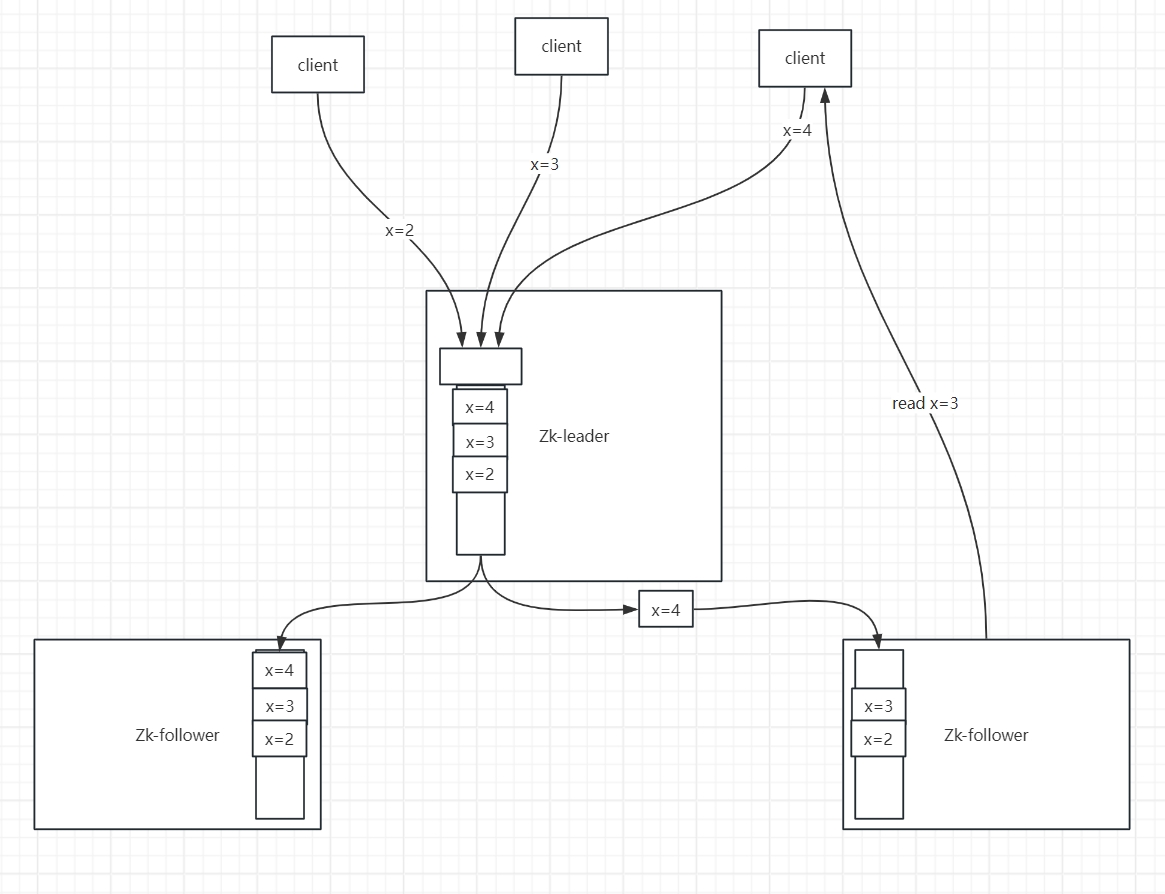
上图中右边的client写入x=4后,从另一个节点读到了x=3。
官方怎么说?
zookeeper官方文档给出的描述是 (https://zookeeper.apache.org/doc/current/zookeeperInternals.html)
The consistency guarantees of ZooKeeper lie between sequential consistency and linearizability. In this section, we explain the exact consistency guarantees that ZooKeeper provides.
Write operations in ZooKeeper are linearizable. In other words, each write will appear to take effect atomically at some point between when the client issues the request and receives the corresponding response. This means that the writes performed by all the clients in ZooKeeper can be totally ordered in such a way that respects the real-time ordering of these writes. However, merely stating that write operations are linearizable is meaningless unless we also talk about read operations.
Read operations in ZooKeeper are not linearizable since they can return potentially stale data. This is because a read in ZooKeeper is not a quorum operation and a server will respond immediately to a client that is performing a read. ZooKeeper does this because it prioritizes performance over consistency for the read use case. However, reads in ZooKeeper are sequentially consistent, because read operations will appear to take effect in some sequential order that furthermore respects the order of each client’s operations. A common pattern to work around this is to issue a sync before issuing a read. This too does not strictly guarantee up-to-date data because sync is not currently a quorum operation. To illustrate, consider a scenario where two servers simultaneously think they are the leader, something that could occur if the TCP connection timeout is smaller than syncLimit * tickTime. Note that this is unlikely to occur in practice, but should be kept in mind nevertheless when discussing strict theoretical guarantees. Under this scenario, it is possible that the sync is served by the “leader” with stale data, thereby allowing the following read to be stale as well. The stronger guarantee of linearizability is provided if an actual quorum operation (e.g., a write) is performed before a read.
Overall, the consistency guarantees of ZooKeeper are formally captured by the notion of ordered sequential consistency or OSC(U) to be exact, which lies between sequential consistency and linearizability.
翻译为:ZooKeeper的一致性保证介于顺序一致性和线性化之间。在本节中,我们将解释 ZooKeeper 提供的精确一致性保证。
ZooKeeper 中的写操作是线性化的。换句话说,每次写入都会在客户端发出请求和接收相应响应之间的某个时间点自动生效。这意味着 ZooKeeper 中所有客户端执行的写入可以以尊重这些写入的实时顺序的方式完全排序。然而,仅仅声明写操作是可线性化的是没有意义的,除非我们也谈论读操作。
ZooKeeper 中的读取操作不可线性化,因为它们可能返回潜在的过时数据。这是因为 ZooKeeper 中的读取不是仲裁操作,服务器将立即响应正在执行读取的客户端。 ZooKeeper 这样做是因为它在读取用例中优先考虑性能而不是一致性。然而,ZooKeeper 中的读取是顺序一致的,因为读取操作似乎按某种顺序生效,而且还尊重每个客户端操作的顺序。解决此问题的常见模式是在发出读取之前发出同步。这也不能严格保证数据是最新的,因为同步当前不是仲裁操作。为了说明这一点,请考虑这样一个场景:两个服务器同时认为它们是领导者,如果 TCP 连接超时小于syncLimit * tickTime,则可能会发生这种情况。请注意,这在实践中不太可能发生,但在讨论严格的理论保证时仍应牢记在心。在这种情况下,同步可能由具有陈旧数据的“领导者”提供,从而允许后续读取也陈旧。如果在读取之前执行实际的仲裁操作(例如写入),则可以提供更强的线性化保证。
简单总结
- 写操作是线性化的
- 读操作不是,这是出于性能考虑(读不是多数读,即quorum read)
- 读操作会保障每个client的写入顺序,这里有点像编译器的as-if-serial语义
- client如果想读到最新的数据可以在read之前调用sync,但是这也不是严格最新,因为sync也不是quorum操作。
如果不是强一致
Zookeeper的读究竟读了啥?Zookeeper的读有这样的保证:
- 你读到的不一定是最新的数据,但一定是过去某个存在过的状态,而不可能是由于崩溃,网络延迟会导致产生某种中间状态,比如某个集群初始状态x=0,y=0 ,client中先写入x=2 后再写入y=3,对于集群内部状态机有如下几种可能:
- x=0,y=0
- x=2,y=0
- x=2,y=3
任何情况下,follower的状态机只会有上面3种,你永远不可能读到x=0,y=3的视图。
2. 将leader视作状态机,在包含全局时钟的前提下将状态机按时间切分,则follower的状态只会出现在leader的状态中。
3. 网络上很多资料将顺序一致性形容为“错的话一起错,对的话一起对” ,这里的对错其实是上帝视角开全局时钟下的判断。这里更重要的两个字是“一起”。即:前面2条描述的状态是对任意follower生效的,或早或晚,follower的状态会追上leader,达到状态视图的完全一致。