一 引入 哈希表的实现大同小异,主要的区别是处理哈希冲突的方式,常用的有:开放定址法,链地址法等。
开放定址法。当通过哈希函数将key映射到表上发现冲突时,通过线性探测或平方探测的方式。此类方法常常无法完全利用空间,比如某些情况下删除元素时只能逻辑删除的问题,
链地址法,又称拉链法。在发生哈希冲突时,将冲突元素做链表,许多语言的标准库中哈希表都采用这种方案。然而这种方案在冲突严重的情况下,会将哈希表的O(1)读写退化为链表的O(N)读写,所以Java中的HashMap会在链表足够长的情况下,转为红黑树。但是无论是链表还是红黑树,内存空间都不会连续,无法充分高速缓存。
本文我们要讨论的布谷鸟哈希没有采用上面两种方案,是一种独特的哈希表模型。
布谷鸟(Cuckoo),即大杜鹃,不自己筑巢,会将卵产在其他鸟类的巢里,让其他的鸟帮助自己孵化和育雏。布谷鸟古人称之为鸠,而它正是“鸠占鹊巢”中的“鸠”。
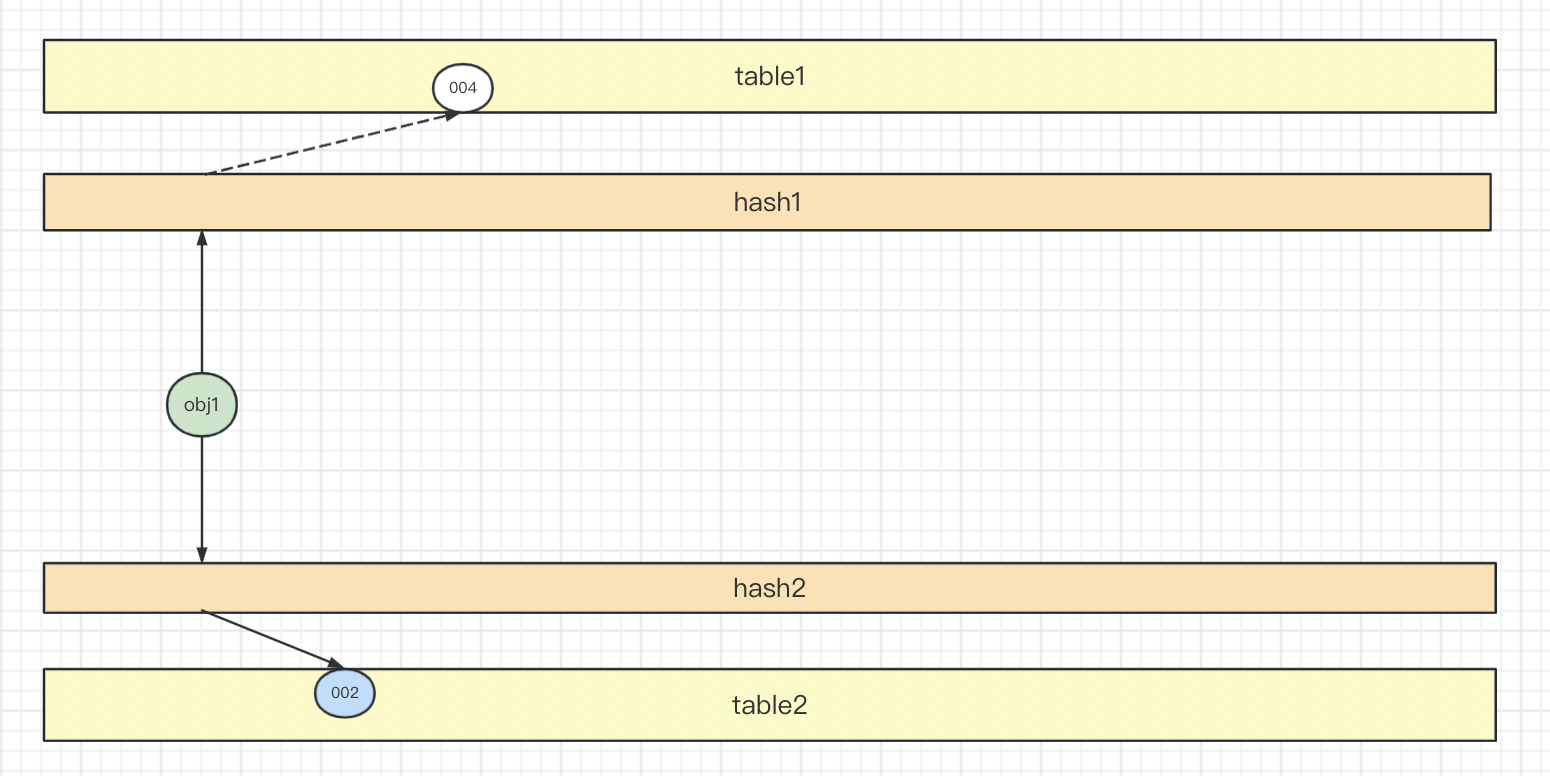
二 基本原理 1. 数据结构 布谷鸟哈希包含两个哈希函数,两套桶。
2. 插入流程
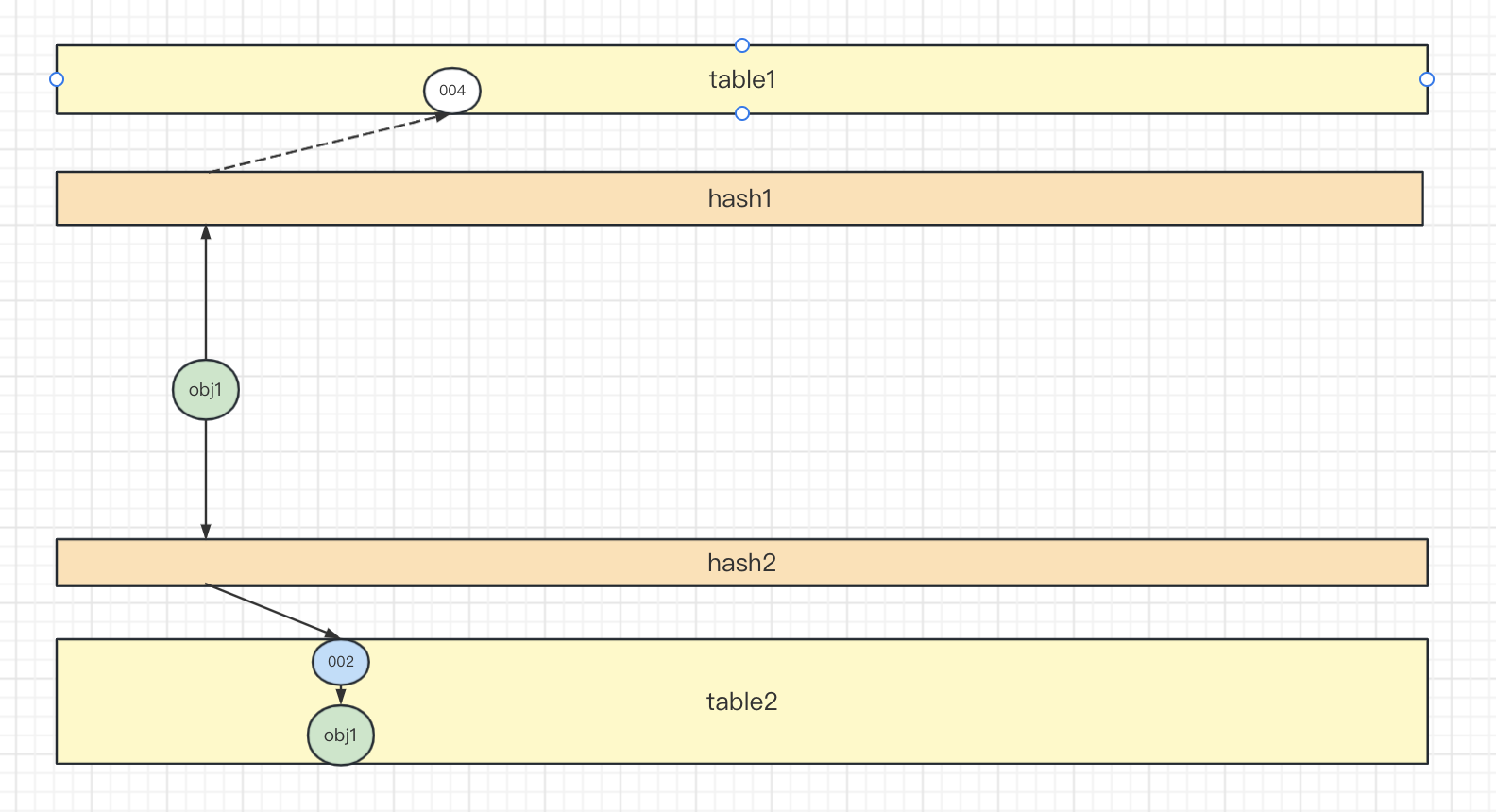
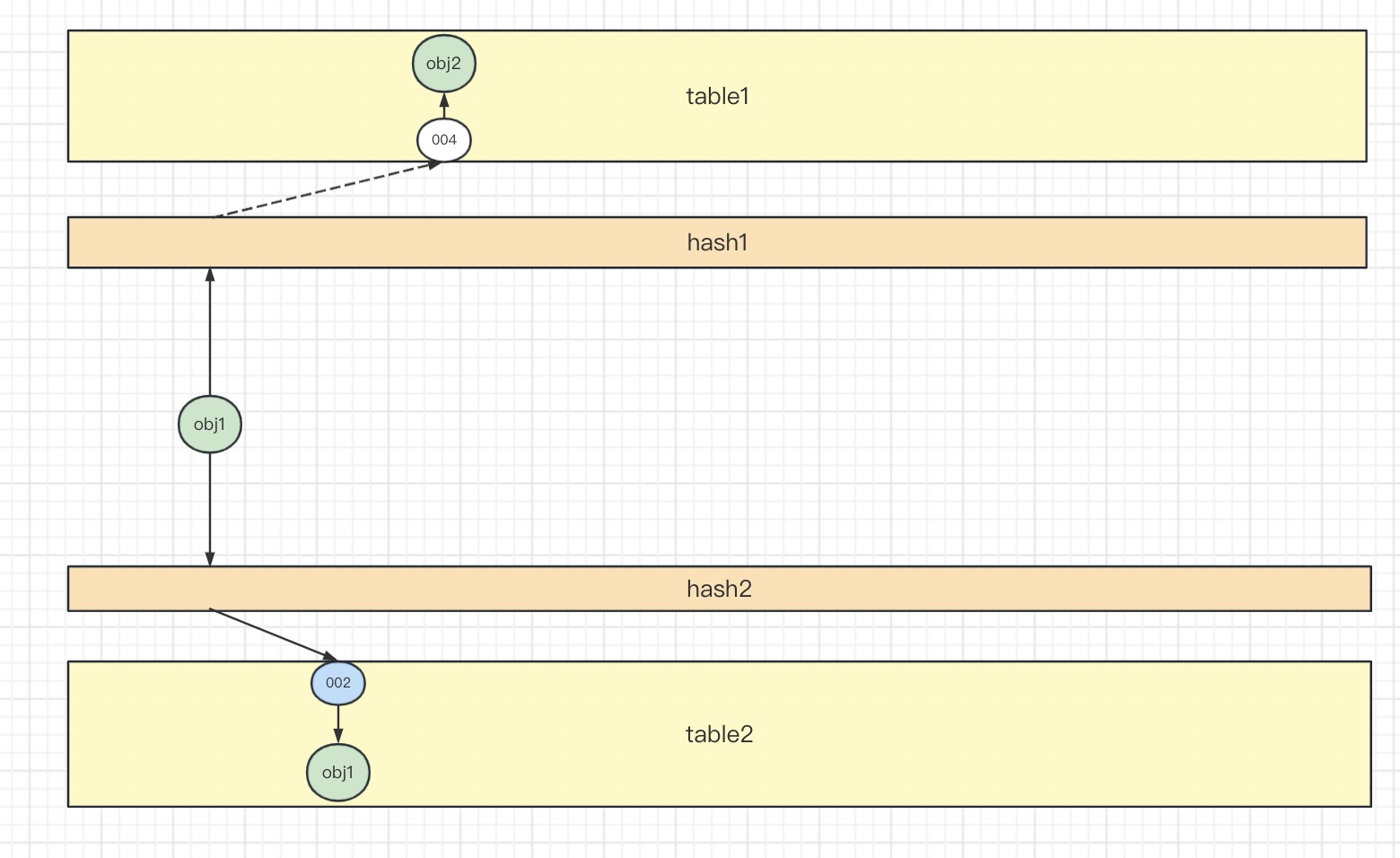
如果两个slot都是空,则随机选择一个插入。这里选择slot 002插入。
如果两个slot中有一个是空,则直接插入空slot。
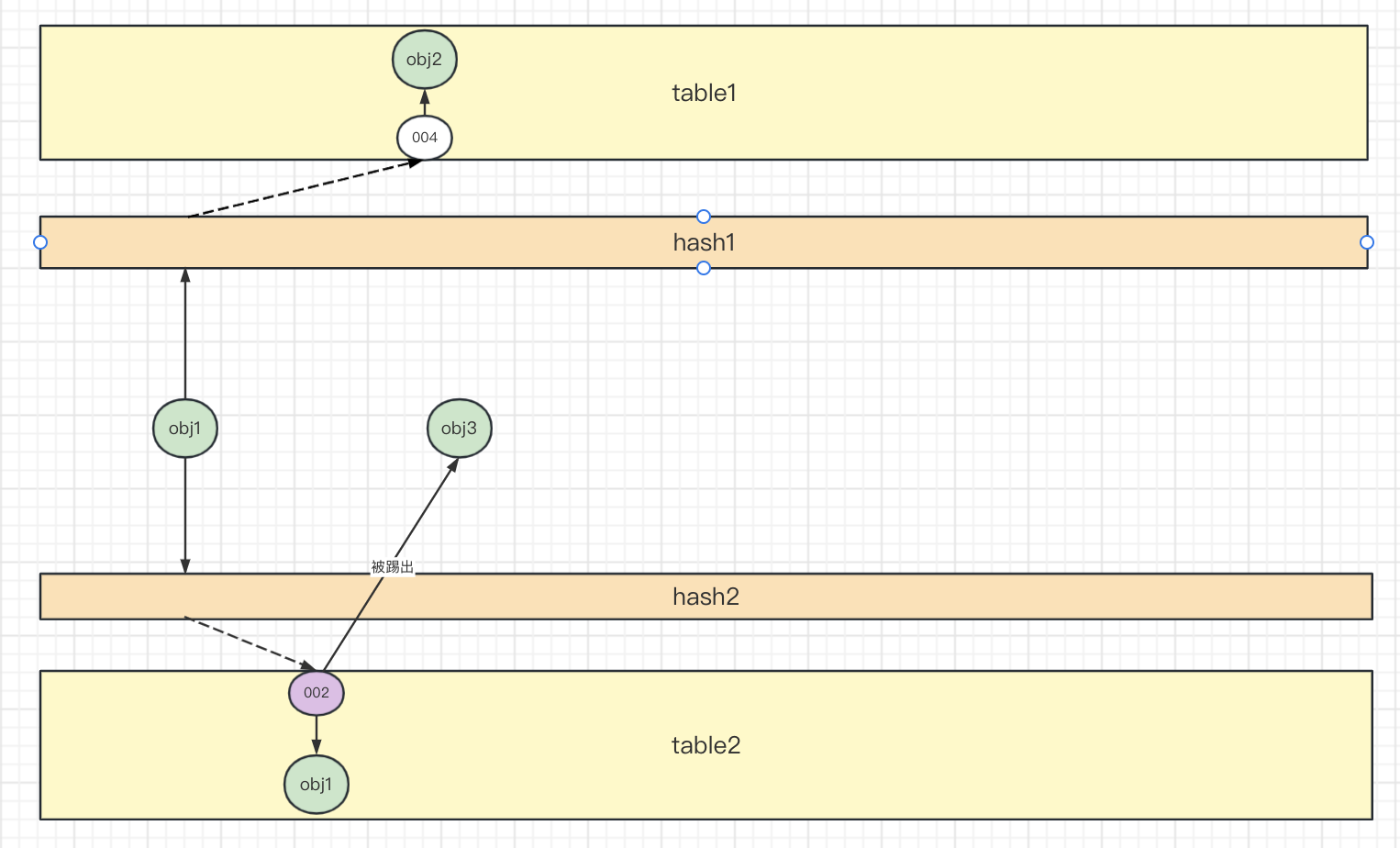
如果两个slot都被插入了,随机选择一个slot“鸠占鹊巢” ,将其slot obj3踢出,自己插入。然后重复上面的步骤尝试插入obj3。
3. 查询流程 布谷鸟哈希的数据结构中,我们的key如果存在,则必定保存在两个hashslot中,两个slot对应的key都和目标不同,则其必不存在于slot中。Table1[Hash1(obj)] 和Table1[Hash2(obj)]
三 应用场景 1.代替布隆过滤器 布隆过滤器用一组哈希函数和一块内存表示一个数据集,用于对集合中数据条目的有无进行快速查询。它虽有一定误报率,但是只使用相当小的内存,对比准确的位图法,可以节约大量内存。
但是布隆过滤器不支持删除。所以有大佬尝试用布谷鸟哈希代替布隆过滤器。相关论文:https://www.cs.cmu.edu/~dga/papers/cuckoo-conext2014.pdf
其相对布隆过滤器的优势在于
支持删除元素
更高的查询效率,尤其在高负载因子时
相比其他支持删除的 Filter 更容易实现
如果期望误报率在 3% 以下,所用空间比 Bloom Filter 少
作为工程实现上的优化在于:
为了提高桶的利用率,使用多路哈希桶。
为了减少内存的使用,只存储 key 指纹。
这里是一个rust的实现
cuckoofilter = "0.5.0"
基本数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 pub struct CuckooFilter <H> { buckets: Box <[Bucket]>, len: usize , _hasher: std::marker::PhantomData<H>, } #[derive(Clone)] pub struct Bucket { pub buffer: [Fingerprint; BUCKET_SIZE], } pub const FINGERPRINT_SIZE: usize = 1 ;pub const BUCKET_SIZE: usize = 4 ;const EMPTY_FINGERPRINT_DATA: [u8 ; FINGERPRINT_SIZE] = [100 ; FINGERPRINT_SIZE];#[derive(PartialEq, Copy, Clone, Hash)] pub struct Fingerprint { pub data: [u8 ; FINGERPRINT_SIZE], } pub struct FaI { pub fp: Fingerprint, pub i1: usize , pub i2: usize , }
指纹和两套哈希函数的结果组合为FaI结构体
怎么计算指纹呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 impl FaI { fn from_data <T: ?Sized + Hash, H: Hasher + Default >(data: &T) -> Self { let (fp_hash, index_hash) = get_hash::<_, H>(data); let mut fp_hash_arr = [0 ; FINGERPRINT_SIZE]; let _ = (&mut fp_hash_arr[..]).write_u32::<BigEndian>(fp_hash); let mut valid_fp_hash : [u8 ; FINGERPRINT_SIZE] = [0 ; FINGERPRINT_SIZE]; let mut n = 0 ; let fp ; loop { for i in 0 ..FINGERPRINT_SIZE { valid_fp_hash[i] = fp_hash_arr[i] + n; } if let Some (val) = Fingerprint::from_data (valid_fp_hash) { fp = val; break ; } n += 1 ; } let i1 = index_hash as usize ; let i2 = get_alt_index::<H>(fp, i1); Self { fp, i1, i2 } } pub fn random_index <R: ::rand::Rng>(&self , r: &mut R) -> usize { if r.gen () { self .i1 } else { self .i2 } } }
插入流程,先计算FaI,尝试将其插入两个表,能插入一个就直接成功。然后按照前面描述的流程,如果两表slot都被占用,则将随机slot挤出。继续为被挤出的slot找位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 pub fn add <T: ?Sized + Hash>(&mut self , data: &T) -> Result <(), CuckooError> { let fai = get_fai::<T, H>(data); if self .put (fai.fp, fai.i1) || self .put (fai.fp, fai.i2) { return Ok (()); } let len = self .buckets.len (); let mut rng = rand::thread_rng (); let mut i = fai.random_index (&mut rng); let mut fp = fai.fp; for _ in 0 ..MAX_REBUCKET { let other_fp ; { let loc = &mut self .buckets[i % len].buffer[rng.gen_range (0 , BUCKET_SIZE)]; other_fp = *loc; *loc = fp; i = get_alt_index::<H>(other_fp, i); } if self .put (other_fp, i) { return Ok (()); } fp = other_fp; } Err (CuckooError::NotEnoughSpace) }
判断元素是否存在,查完1查2。
1 2 3 4 5 6 7 8 pub fn contains <T: ?Sized + Hash>(&self , data: &T) -> bool { let FaI { fp, i1, i2 } = get_fai::<T, H>(data); let len = self .buckets.len (); self .buckets[i1 % len] .get_fingerprint_index (fp) .or_else (|| self .buckets[i2 % len].get_fingerprint_index (fp)) .is_some () }
删除,1或者2遇到命中就删。
1 2 3 4 5 6 pub fn delete <T: ?Sized + Hash>(&mut self , data: &T) -> bool { let FaI { fp, i1, i2 } = get_fai::<T, H>(data); self .remove (fp, i1) || self .remove (fp, i2) }
布谷鸟哈希在应用中主要用于代替布隆过滤器。