为什么要对象存储?
传统上我们使用基于块的存储和文件系统。基于块的文件系统使用偏移表(对于linux体系就是superblock + inode)来存储文件位置,它们将每个文件分成小块(linux体系的page,通常大小为 4KB),并将每个块的字节偏移量存储在一个大表中。在目前数据量要扩展到PB级的情况下。这种方式缺乏扩展性。
为了解决这个问题,一些组织已经部署了可横向扩展的文件系统,例如 HDFS。 这一定程度上解决了可扩展性问题,但这类文件系统大多数都依赖于复制来保护数据。通常需要保存 3 个副本才能保证足够的可靠性。10 PBs 级的数据通常需要大量的磁盘和服务器设备,总体成本比较高。
对象存储为访问时延无极端苛刻要求的海量数据文件存储提供了一个高吞吐量、高可扩展、低成本的方案。对象存储将数据本身与元数据标记和唯一标识符绑定在一起,存储在扁平的地址空间中,从而更容易跨区域查找和检索数据,而且还有助于提高可扩展性。对象存储可以在单个命名空间中扩展到 10~100 PBs。 对象存储不使用数据复制,而是使用纠删码等技术来保护数据、最大化可用的磁盘空间,从而降低成本。
| 对象存储 | (基于块的)文件存储 |
|---|---|
| 大数据量和高流吞吐量要求场景性能最佳 | 更适合小数据量随机访问 |
| 数据可以跨多个区域存储 | 数据通常在本地共享 |
| 轻松扩展到 10 PBs 以上 | 可能扩展到数百万个文件,容量很难达到 PB |
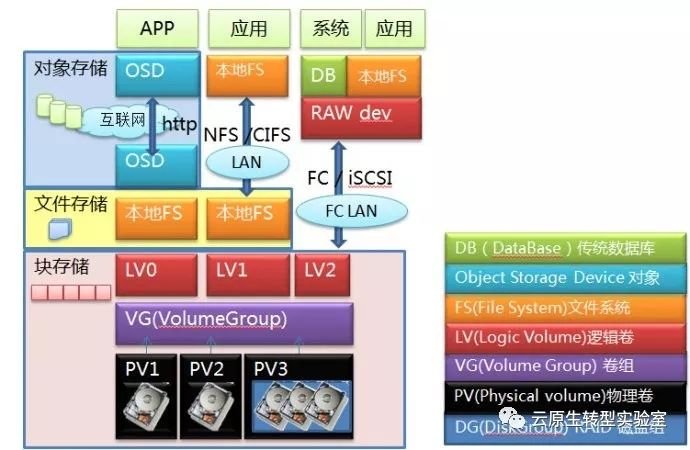
这里是ceph的架构图可以用来参考对象存储和块存储,文件存储的关系。
Minio 简介
Mino 是基于 Apache License v2.0 协议完全开源、兼容 Amazon S3 API、高性能、可扩展、低成本的对象存储软件,并提供包括故障诊断、安全更新和bug修复、7x24小时支持等在内的订阅服务。
Minio 的架构
Minio 采用分布式的架构,把数据分片和纠删码编码后的校验数据分片一起均匀存储到多个服务器上的 JBOD(just a bunch of disks) 磁盘中,不需要磁盘RAID。在存储和读取对象数据的同时存储和读取校验Hash值,自动纠正服务器或磁盘故障、静默数据坏块。对象存储目标是降低成本,对象存储更倾向于直接面向磁盘部署,而不是面向文件系统或者Raid。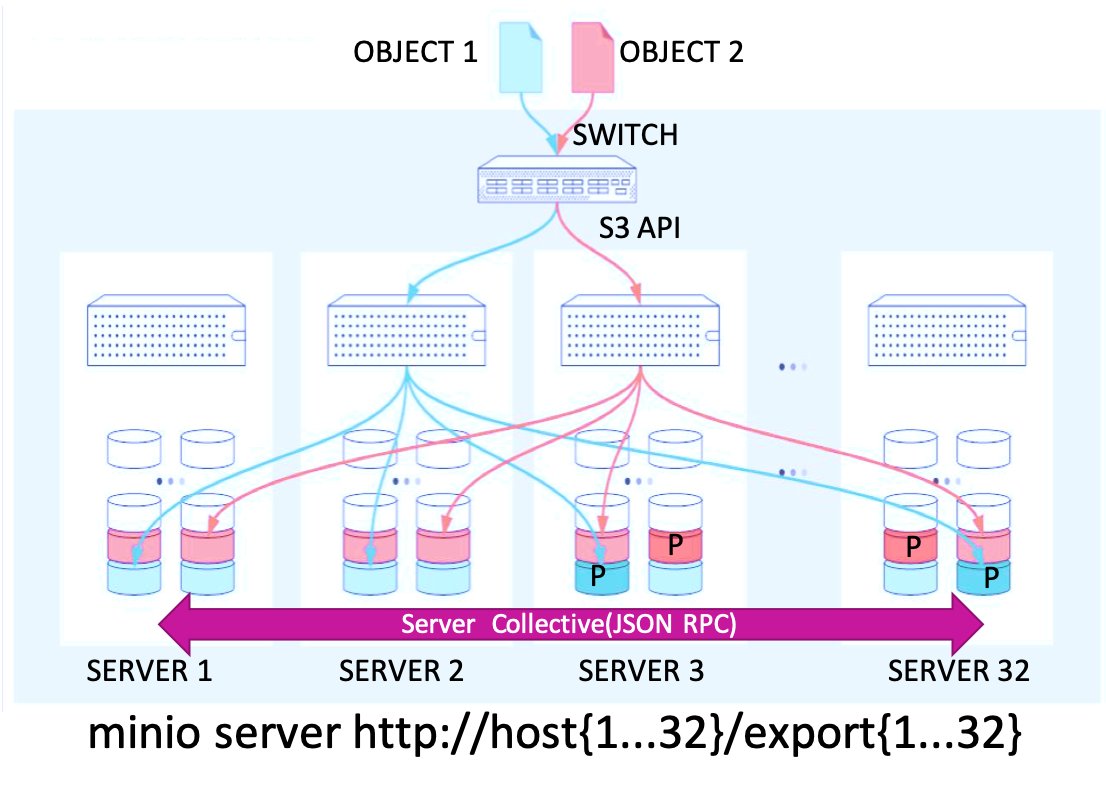
特点
Minio 主要有以下特点:
- 纠删码分布式对象存储
- 缺省数据分片和编码分片数相同,即 k=m,磁盘占比为 2.00(低于 HDFS 的 3.00),能容错 50% 的服务器故障
- 可以设置全局或对象级的数据和校验分片数,2 <= m <= n/2,磁盘占比在 1.14~2.00 之间
- SHA-512 Hash 检测静默数据坏块
- 针对 x64 和 ARM CPU 的 SIMD 指令优化
- 兼容AWS S3 API
- 还提供“先写后读”的严格一致性
- 作为其他存储的 S3 协议网关
- AWS/GCS/Azure/OSS
- HDFS/NAS
可靠性
minio基于纠正删码来保护数据。为了保证分布式存储的性能,Mino 把每 n(受环境变量 MINIO_ERASURE_SET_DRIVE_COUNT 控制,必须是 4~16 之间,缺省取尽可能大的值)块磁盘构成一个纠删组(相当于stripe)。对象的原始数据和校验数据被分片后存储在每个纠删组的各个磁盘上与对象同名的目录中(下图中的part.n),并附上对象的元数据(下图中的xl.json)。第一块数据磁盘序号由对象名称的 Hash 值确定,这样就可以把多个对象的原始数据分片均匀分布在所有磁盘上,从而均衡地利用所有磁盘的读写能力和容量。
基本概念
- S3——Simple Storage Service,简单存储服务,这个概念是Amazon在2006年推出的,对象存储就是从那个时候诞生的。S3提供了一个简单Web服务接口,可用于随时在Web上的任何位置存储和检索任何数量的数据。
- Object——存储到 Minio 的基本对象,如文件、字节流,Anything…
- Bucket——用来存储 Object 的逻辑空间。每个 Bucket 之间的数据是相互隔离的。
- Drive——部署 Minio 时设置的磁盘,Minio 中所有的对象数据都会存储在 Drive 里。
- Set——一组 Drive 的集合,分布式部署根据集群规模自动划分一个或多个 Set ,每个 Set 中的 Drive 分布在不同位置。
- 一个对象存储在一个Set上
- 一个集群划分为多个Set
- 一个Set包含的Drive数量是固定的,默认由系统根据集群规模自动计算得出
- 一个SET中的Drive尽可能分布在不同的节点上
单机部署
我们可以使用podman/docker简单部署一个单节点单磁盘实例:
1 | podman run -p 9000:9000 -p 9001:9001 --name minio \ |
启动完毕后,即可在本地9001端口访问console,使用admin/admin123456登录。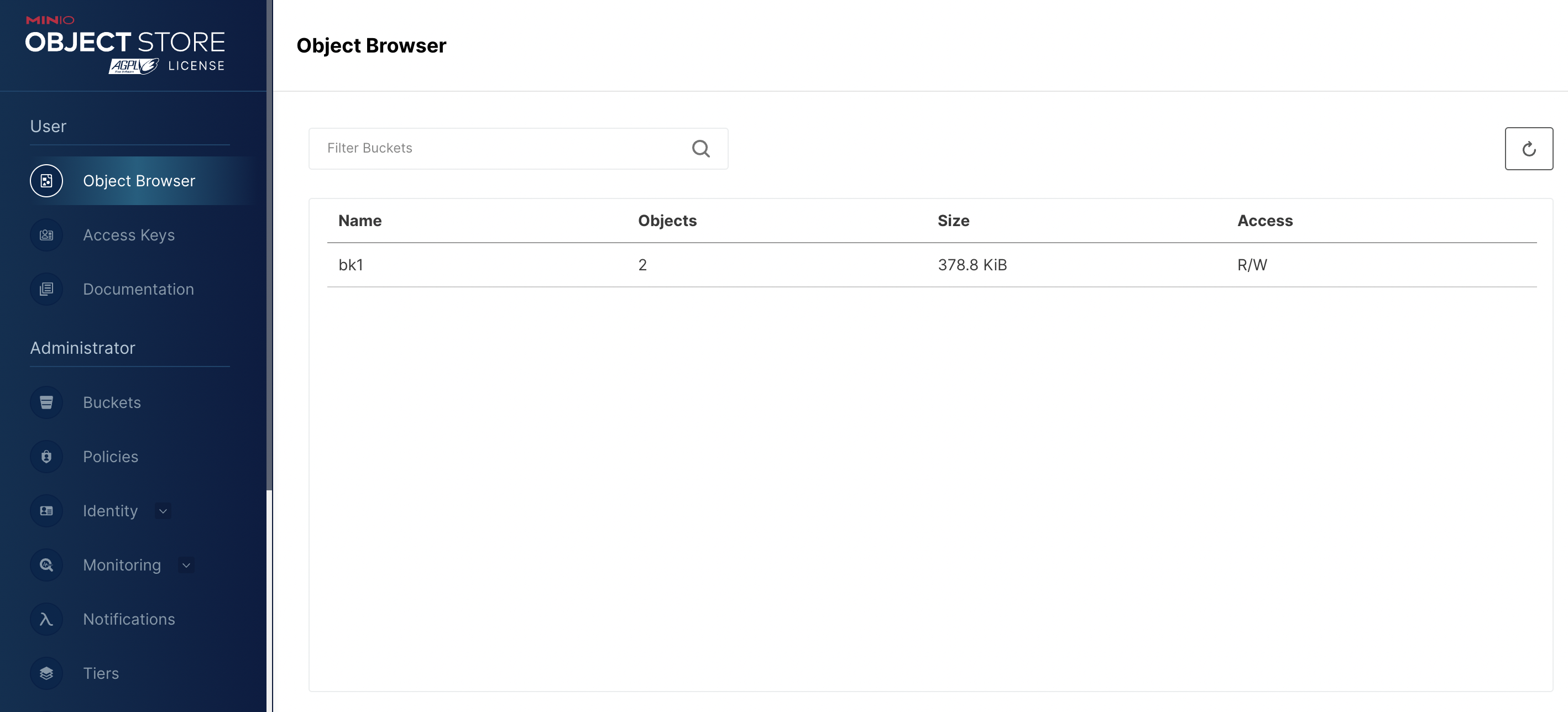
我们可以在这里创建bucket,创建accesskey。
使用awscli
如前面描述的minio兼容s3协议,所以我们可以使用awscli来使用minio。
安装awscli
1 | pip3 install awscli |
配置awscli
1 | aws configure |
里面会让我们配置ak,sk,配上我们前面创建的ak。
1 | aws configure set default.s3.signature_version s3v4 |
这个命令调整签名算法适配minio。
列出bucket
1 | aws --endpoint-url https://node9:32000 s3 ls |
列出bk1这个bucket下的Object
1 | aws --endpoint-url https://node9:32000 s3 ls s3://bk1/ |
上传Object
1 | aws --endpoint-url https://node9:32000 s3 cp abc.txt s3://bk1/ |
生成签名url
1 | aws --endpoint-url http://node9:32000 s3 presign s3://bk1/abc.txt |
存储背后
当我们进入容器后可以看到:
1 | bash-4.4$ ls |
这里可以看到其基本存储结构:
{bucket} -> {object} -> {元信息}
{数据} -> {分片}
假设我们部署三个节点,这里即使删除一个节点的数据文件,依然能正常访问数据。
多节点部署
基本能满足需求了,那么如何部署集群呢?我们这里直接使用helm部署了。
添加仓库
1 | helm repo add minio https://charts.min.io/ |
先pull到本地改下value配置
1 | helm pull minio/minio |
console的初始密码
1 | rootUser: "admin" |
副本数,我这里启动了三节点,每节点一个磁盘
1 | # Number of drives attached to a node |
创建namespace
1 | kubectl create ns |
启动集群
1 | helm install minio . -n minio |
启动完成
1 |
|
和单机集群一样,登录控制台,配置ak即可使用s3api访问。