本篇我们详细学习Cypher。
什么是cypher?
类似sql专用于结构化数据,Cypher(后面简称cql)是一种专用于图的声明查询语言。我们通常会使用cql操作neo4j的数据,这比直接操作图数据库的节点和边更高效。
怎么使用cql?
一种方式就是类似java 的MySQL driver
1 | <dependency> |
我们这里配置maven java driver。
使用driver连接neo4j
1 |
|
然后就可以简单的执行cql
1 |
|
browser
也可以访问neo4j自带的 browser,启动neo4j后可以访问 http://localhost:7474/browser/ 即可访问本地的图浏览器
可以作为dbms使用,上面可以输出cql,并且带有补全和语法高亮,非常好用。
语法
基本概念
- 节点使用
()表示 - 属性使用
{}表示 - 关系使用
[]表示- 显式关系:
(a)-[r:Like]->(b) - 隐式关系:
(a)--(b)
- 显式关系:
创建节点
格式
1 | create (nodename:nodelabel { property }) |
其中:
- nodename为节点名可以省略
- nodelabel为标签,可以添加多个标签
- property为键值对,其中字符串类型需要用单引号包裹,整数和布尔型不需要
样例
1 | create (n:Student {name:'zhangsan'}) |
也可以创建没有属性的节点
1 | create (n:Student) |
也可以创建没有标签的节点
1 | create (n) |
或者是只有属性没有标签的节点
1 | create (n {name :'zhangsan'}) |
或者是多个标签的节点,多个标签用 : 分割
1 | create (n:Student:Person {name:'zhangsan',age:22}) |
查询节点
查询需要用到match和return 两个关键字。
1 | MATCH |
其中
- match类似sql中的from ,sql中的from后面通常跟随一个表,或者一个查询集,表示后面的数据筛选的源头。cql中并没有表的概念,或者可以理解为,所有数据全部在同一个表中,如果我们的查询不添加任何标签(label)图数据库将扫描全部节点。因此,无论是出于便于管理还是性能原因,我们创建节点通常都会根据业务打上标签,查询时match后跟我们要查询的标签。
- return 则类似sql中的select,这里是对数据的进一步处理,包含结果集字段的筛选,再加工。在cql中我们可以选择属性返回,也可以直接返回节点
查询返回节点
1 | match (n:Student) return n |

这里节点被直接以图的形式展示在browser中。
查询返回属性
1 | match (n:Student) return n.name,n.age |
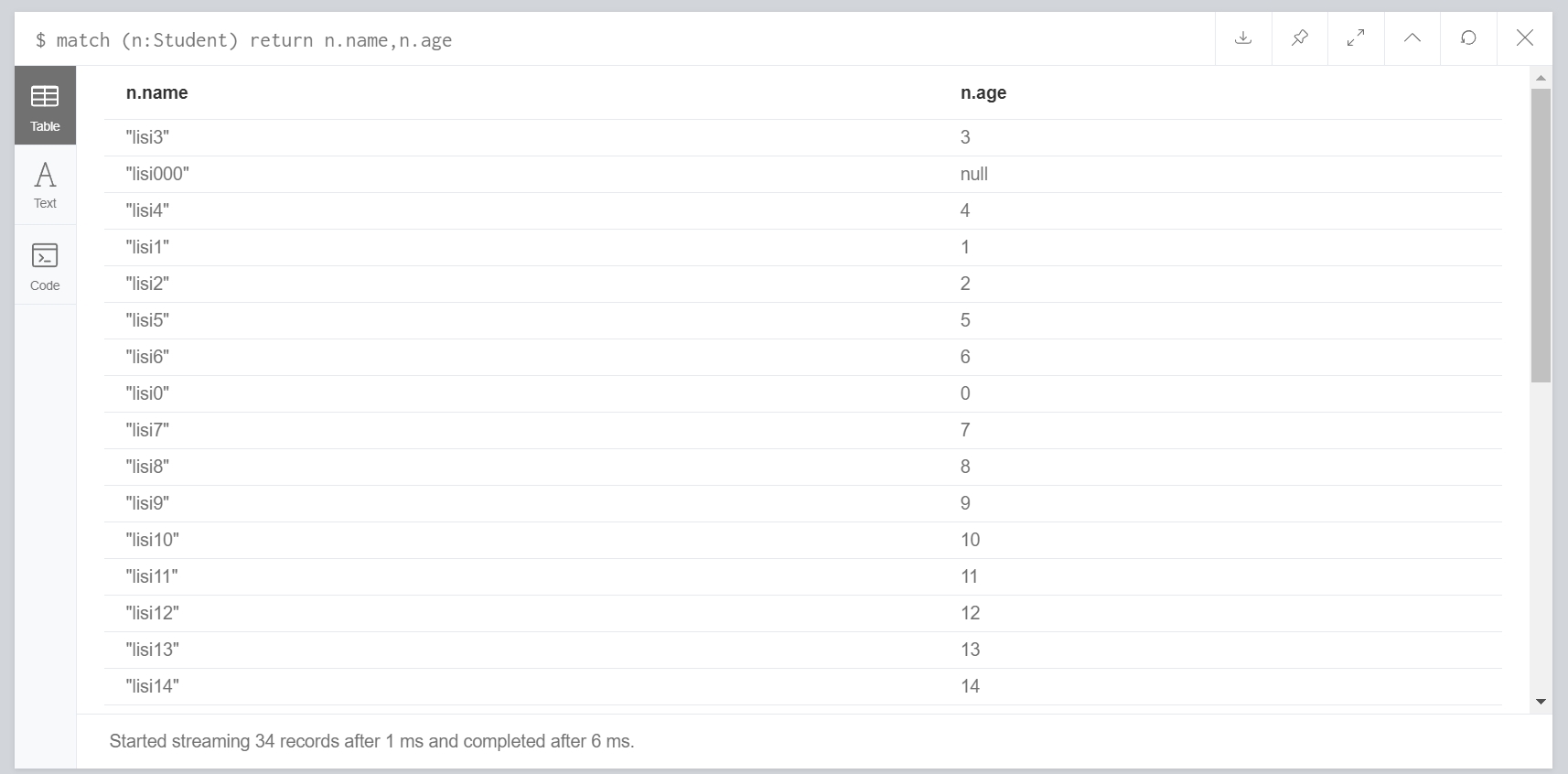
这里的返回则比较类似结构化数据了
where子句
类似于sql的where,用于给数据集添加过滤条件,通常跟 match 一起用。
where支持众多条件:
相等
1
match (m:Student) where m.name = 'zhangsan' return m
这里没啥可以说的,基本都会用。
模糊查询
1
match (m:Student) where m.name =~ 'lisi.*' return m
这里就跟sql有一些区别了。sql的
like在cql中是=~。条件中的%也被替换为.*大于小于
- 不等于 <>
- 大于 >
- 小于 <
过于常见,这里就不举例了。
条件之间的关系支持:
- and
- or
- not
- xor
删除节点
可以配合match 和 where 一起使用
1 | DELETE <node-name-list> |
例1:删除所有节点:
1 | match (m) delete m |
例2:删除所有年龄大于22岁Student
1 | match (m:Student) where m.age > 22 delete m |
需要注意的是,如果节点包含关系,则会删除失败,必须先删除关系再删除节点,或者是节点关系同时删除。后面我们会详细讨论关系相关的细节。
Set
set可以用于修改节点的标签或是属性
修改lisi的年龄为24
1 | match (n:Student) where n.name = 'lisi' set n.age = 24 |
给lisi添加标签Teacher
1 | match (n:Student) where n.name = 'zhangsan2' set n:Teacher |
Remove
用于删除属性
1 | match (n:Student) where n.name = 'zhangsan' remove n.age |
order by
排序字段也和sql完全一致
1 | order by |
Union
合并两个结果集,和sql也一致,这里要求两个结果集字段相同。
1 | match (n:Student) where n.name = 'zhangsan' return n.name |
limit skip
类似sql的offset,这里改为了skip
1 | match (n:Student) return n limit 10 |
merge
merge和create非常类似,都是创建节点或者关系,但是有一点非常重要的区别:当执行create时,即使要创建的节点存在也会创建;但是merge则不会创建。这里的存在意味着所有属性,标签完全相同。
关系
如果不能创建关系,那也就谈不上图数据库。
如何创建关系?
- 在创建节点的同时创建关系
这样的语句会在创建节点的同时创建关系。
1 | create (<node_name1>:<node_label>)-[<relation_name>:<relation_label>]->(<node_name2>:<node_label>) |
其中[]之间的是关系,有向图的方向表示为-[]->这样的箭头,箭头右边的是被指向的节点。
例子:
1 | create (p1:People)-[r:Like]->(p2:People) |
还可以为关系添加属性
1 | create (c1:City)-[r:Path{distance:100}]->(c2:City) |
也可以不指定标签
- 创建节点后再创建关系
如果是在同一个cql中1
2
3create (c1:City)
create (c2:City)
create (c1)-[r:Path]->(c2)
如果是想在不同的cql/事务中:
1 | create (c:City {name:'shanghai'}) |
1 | match (c1:City),(c2:City) |
如何查询关系
我们使用match来匹配其关系
1 | match (c1:City)-[r]->(c2:City) |
match中我们显式指定出发节点和目标节点的标签和关系的标签,也可以不指定:
1 | match (c1)-[r:Like]->(c2) |
也可以匹配多种关系
1 | match (c1)-[r:Like|:Love]->(c2) |
匹配多个关系
1 | match (c1)-[r1:Like]->(c2)-[r2:Love]->(c3) |
支持匹配路径的模式
1 | match (c1)-[r:Like|:Love]->(c2) |
多重路径
1 | match (c1)-[r:Like*2]->(c2) |
如何表示权重图?
neo4j原生不支持权重图,但是我们可以用属性实现类似的效果。
1 | create (c1:City)-[d:Path{distance:1000}]->(c2:City) |