聚合
1 | import pandas as pd |
如果前面忘记配置name为index就执行聚合,name列无法聚合将会报出警告
1 | /tmp/ipykernel_28675/1256569030.py:1: FutureWarning: The operation <function mean at 0x7ff19c51c4c0> failed on a column. If any error is raised, this will raise an exception in a future version of pandas. Drop these columns to avoid this warning.If any error is raised, this will raise an exception in a future version of |
也可以聚合多个聚合函数。
1 | df.groupby('team').agg({'Q1':['min','max']}) |
分组百分位:
1 | df.groupby('team').quantile(0.9) |
多个条件聚合会产生二层索引
1 | df.groupby(['team', df.mean()>=60]).count() |
过滤器
根据列名选择过滤
1 | df.filter(items=['Q1', 'Q2']) # 选择两列 |
基于正则,选择轴0为行,选择轴1为列
1 | df.filter(regex='Q', axis=1) |
修改数据
直接使用索引赋值
1 | df.iloc[0,2] |
批量修改,可以配合条件矩阵
1 | df[df.Q1 < 60] = 60 |
添加列
1 | df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 |
数据追加
append可以将两个DataFrame二合一。df.append()方法可以轻松实现数据的追加和拼接。如果列名相同,会追加一行到数据后面;如果列名不同,会将新的列添加到原数据。
1 | df.append(df) |
也可以concat
1 | pd.concat([df,df]) |
merge
类似sql的join
1 | (base) fenix@fenixs:~/py/scrawpy$ cat d1.csv |
1 | d1 = pd.read_csv('d1.csv',names=['name','age','cid'],index_col='name') |
数据透视
数据透视可以帮我们找出列与列之间的关系:
1 | df = pd.DataFrame({ |
堆叠
数据的堆叠也是数据处理的一种常见方法。在多层索引的数据中,
通常为了方便查看、对比,会将所有数据呈现在一列中;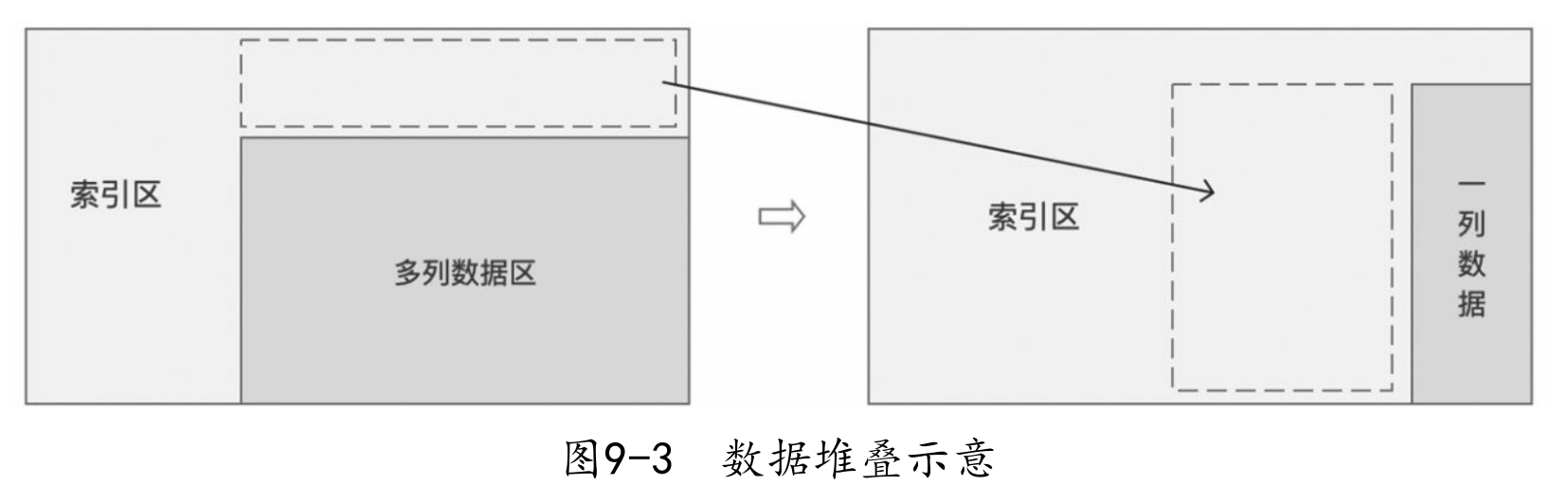
1 | df = pd.read_excel('team.xlsx') |
数据堆叠可以简单理解成将多列数据转为一列数据
堆叠和解堆的本质如下。
- 堆叠:“透视”某个级别的(可能是多层的)列标签,返回带有索
引的DataFrame,该索引带有一个新的行标签,这个新标签在原
有索引的最右边。 - 解堆:将(可能是多层的)行索引的某个级别“透视”到列轴,从
而生成具有新的最里面的列标签级别的重构的DataFrame。
时序数据
s.rolling()是移动窗口函数,此函数可以应用于一系列数据。
1 | s = pd.Series(range(1, 7)) |
我们创建随机数时序样本看看
1 | df = pd.DataFrame(np.random.randn(30, 4), |
我们使用时间偏移作为周期,2D代表两天
1 | df.rolling('2D').mean() |
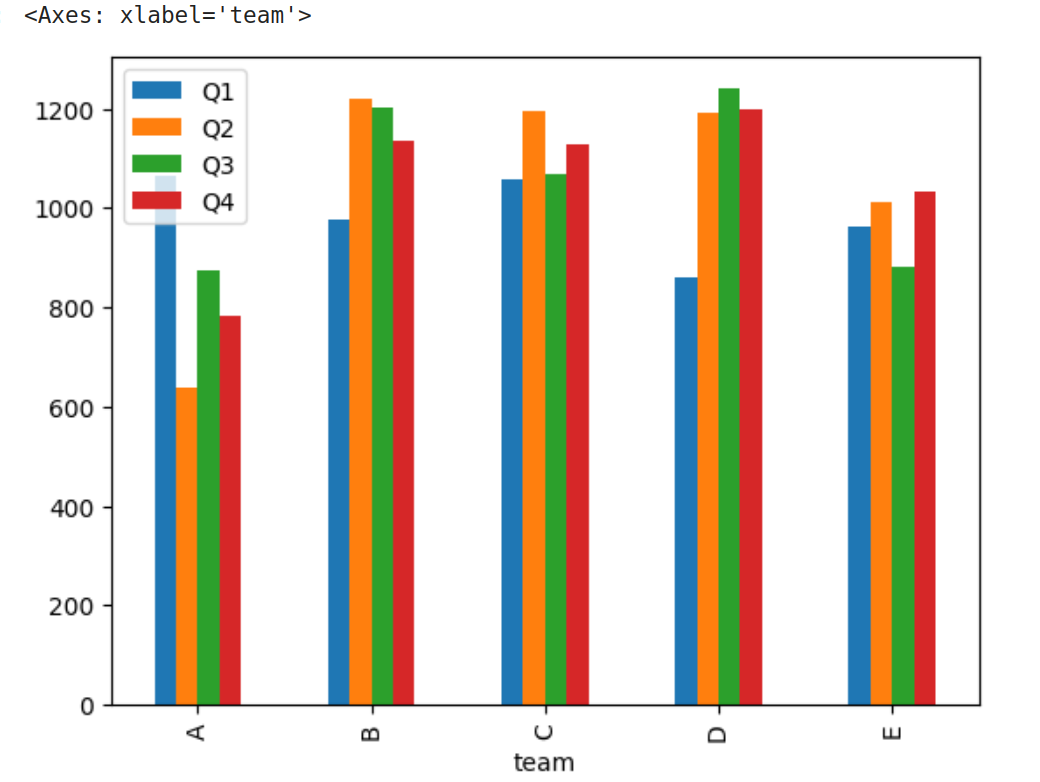
可视化
按照team分组后的柱状图
1 | df.groupby('team').sum().plot.bar() |
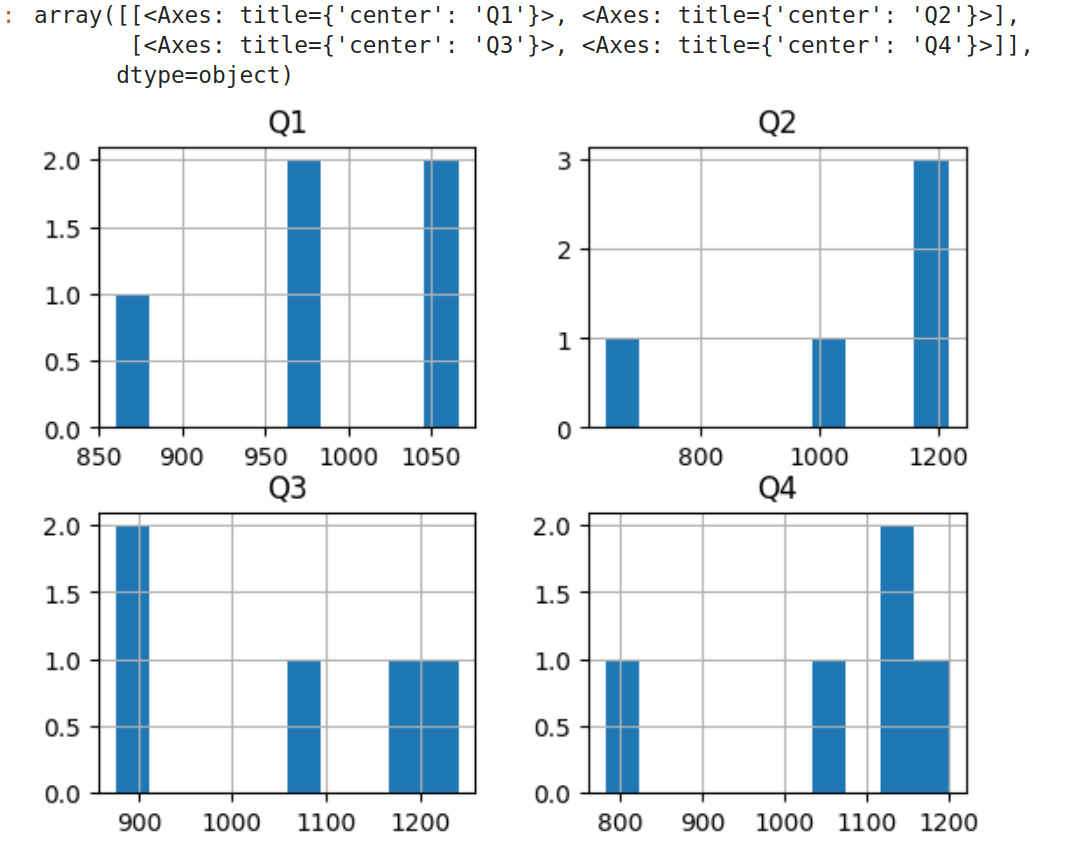
分为Q1-Q4的直方图
1 |
|
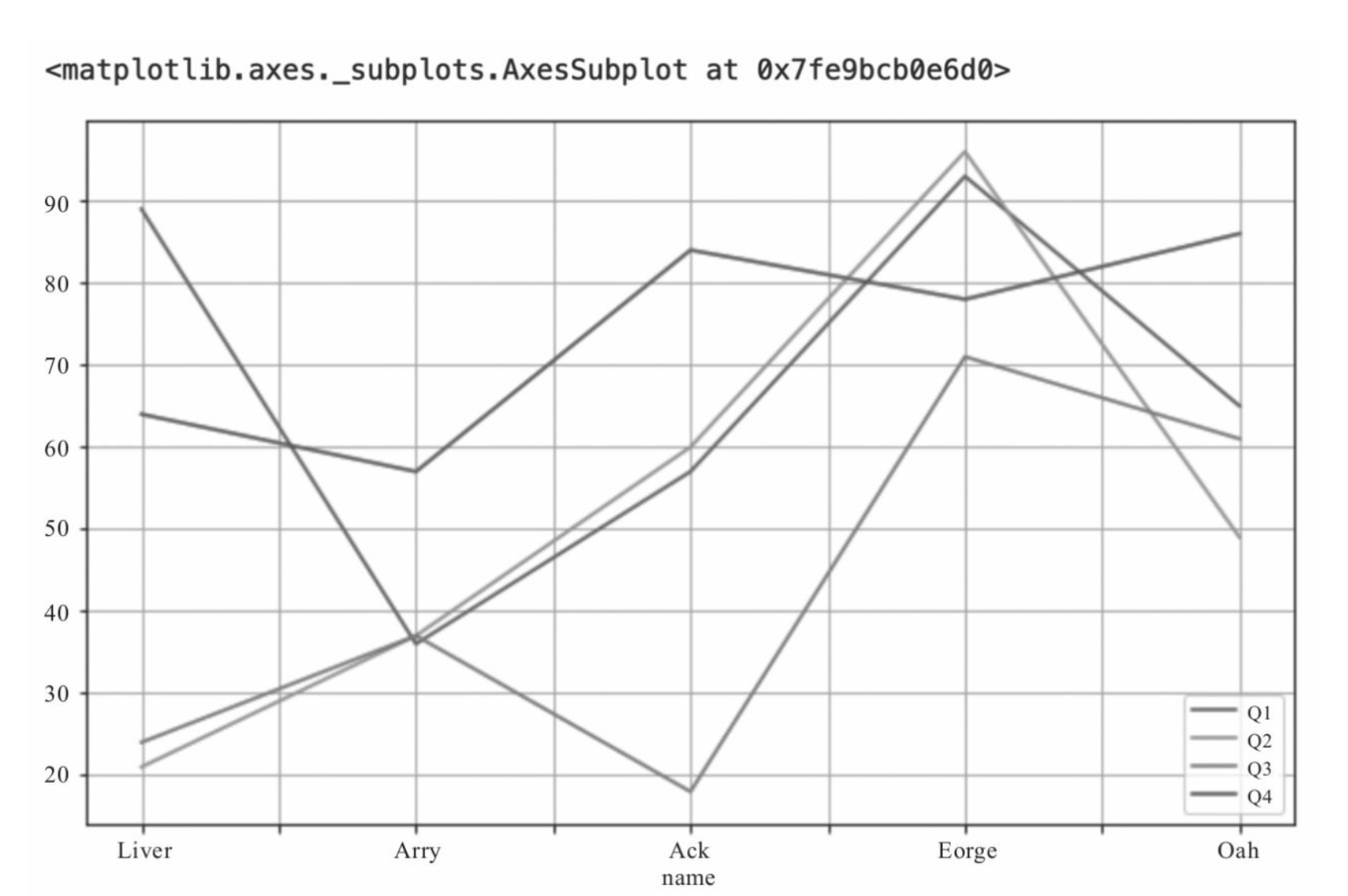
df.plot() 可以传入kind参数
1 |
|
线条样式
style可指定图的线条等样式,并组合使用:
df[:5].plot(style=’:’) # 虚线
df[:5].plot(style=’-.’) # 虚实相间
df[:5].plot(style=’–’) # 长虚线
df[:5].plot(style=’-‘) # 实线(默认)
df[:5].plot(style=’.’) # 点
df[:5].plot(style=’*-‘) # 实线,数值为星星
df[:5].plot(style=’^-‘) # 实线,数值为三角形
背景辅助线
1 | df.set_index('name').head().plot(grid=True) |