原文链接 https://fasterthanli.me/series/reading-files-the-hard-way/part-1
每个人都知道如何使用文件。您只需打开文件资源管理器、Finder, 或文件管理器,然后“砰”的一声——里面塞满了文件。有文件夹和 眼睛所能看到的范围内的文件。这是真正的 filapalooza。我从来没有听到过有人抱怨他们的计算机上没有足够的文件。
但是什么是文件?读取文件到底意味着什么?
这就是我们这个系列的文章要找出的答案。首先,通过最简单的方式读取文件,最用户友好的方式,然后剥离抽象层,直到我们越来越深入直到进入野兽的内脏。
就本文而言,我们对特定文件感兴趣:/etc/hosts 。 这是大多数 Unix-like 系统中都会存在的一个文件,用于映射域名(如 example.org) 到 IP 地址(如 127.0.0.1)。它还有精彩的背景故事。 要阅读它,我们只需使用 GUI:
先决条件
在我们继续之前:如果您想继续阅读本文,您需要一个Linux系统。一个真正的Linux,而不是 WSL1。如果您已经在运行 Linux,那就太好了!如果不, 我建议设置一个Manjaro虚拟机。
如果您以前从未设置过虚拟机,VirtualBox 就可以完成这项工作,而且使用起来相当容易。事实上,我正是用VirtualBox 中的 Manjaro 来写这篇文章的:
使用默认设置的基本安装足以应付本文文章的一部分。 Ubuntu 或 Fedora 安装也可以正常工作,并且 WSL2 可能也可以工作。
好吧,让我们回到正题吧!
处理文件的命令行工具
到目前为止,我们已经打开文件管理器并成功读取了文件。如果这是我们唯一的 有了处理文件的经验(我希望!),我们的心中的文件心智模型可能如下所示:

…但文件实际上并不存在于图形用户界面中。他们住.. 某处,在更深,更深的某处。我可以证明一下。
如果我们切换到文本终端,并完全关闭 GUI,我们仍然可以访问 文件:
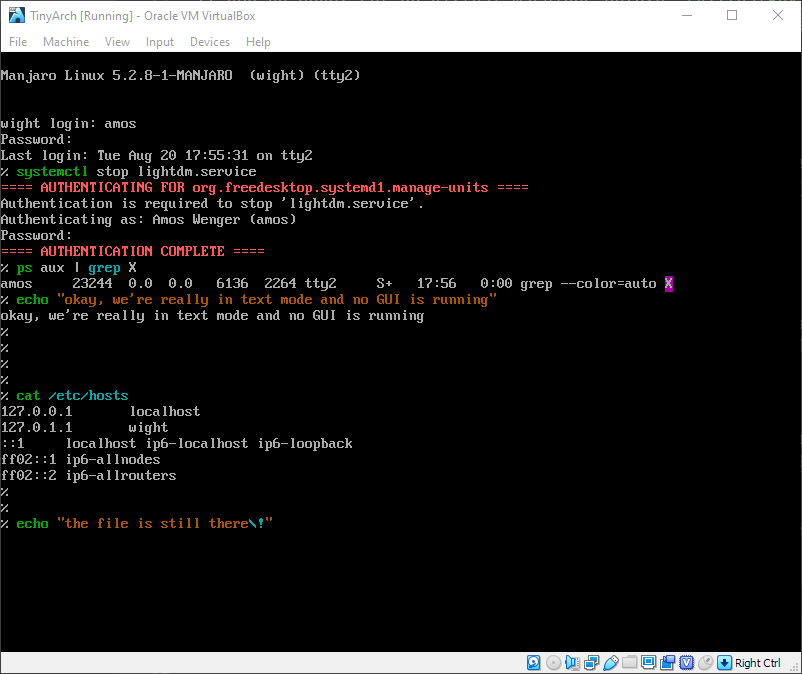
这是完全相同的文件。我不打算在这里展示它,但是如果我们编辑或删除 从 GUI 或文本终端打开文件,更改将反映在各处。这说明它们必须指向同一位置。
我们的心智模型可以升级到更加优越的:
我们学到了什么?
无论我们是否使用图形工具(如鼠标垫)或命令行工具(如 cat),类似 /etc/hosts 的名称始终引用同一个文件。
使用node.js读取文件
到目前为止,我们一直在手动读取文件(无论是图形方式,还是使用 终端)。这一切都很好,但是如果您想读取大量文件怎么办?
让我们尝试一下node.js:
JavaScript code
1 |
|
运行这段代码会得到以下输出:
1 |
|
这看起来根本不像文本。事实上,它在输出中说得对: 它只是一堆字节。它们可以是任何东西!我们只是选择将它们解释为文本。像 cat 这样的终端命令通常是面向文本的, 所以他们通常假设我们正在处理文本文件。
如果我们想要文本,我们将不得不将这些字节解释为一些 文本编码 - UTF-8 听起来像是一个安全的选择。 幸运的是,node.js 带有一个字符串解码器工具:
JavaScript code
1 |
|
运行此命令会得到预期的输出:
1 |
|
但在这里,我们走了很长的路回家,只是为了表明一个观点。你其实可以 将文件的编码直接传递给 readFileSync,这使得 代码更短。
JavaScript code
1 |
|
这给出了完全相同的输出。而不是返回 Buffer, readFileSync 现在直接返回 String。一切都工作地很好。
如果我们在非文本文件上使用此代码会发生什么?例如,/bin/true ?
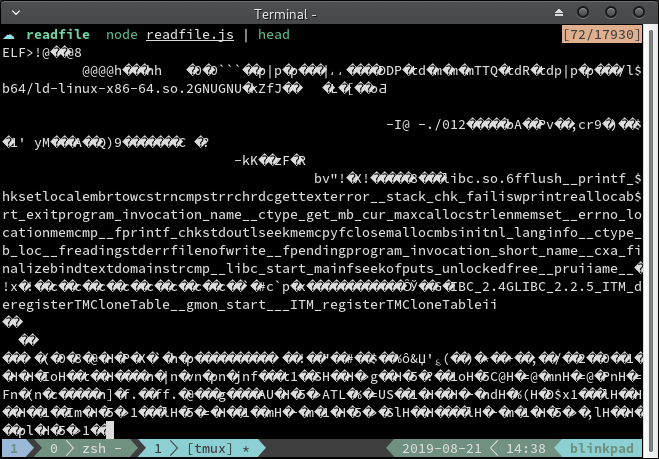
虽然里面有一些字符串,但是输出都是乱码 并填充替换字符。它甚至弄乱了我的终端, 所以我后来不得不使用命令reset.
顺便说一句:如果我们真的想从 /bin/true 获取字符串, 我们本来可以使用 strings 命令(令人震惊!):
Shell session
1 |
|
我们学到了什么?
文件只是字节的集合。要对它们做任何有用的事情,我们必须解释它们。 UTF-8 是一种常见的文本编码。
使用 Rust 读取文件
让我们进入编译语言的领地,度过一段热烈的时光。
如果我们使用cargo new readfile,请进入readfile目录并编辑 src/main.rs是这样的:
Rust code
1 |
|
酷熊的热心小贴士
注意:正如 Pascal 所指出的 出,我们 可以只使用 std::fs::read_to_string。
但是这样我们就学不到那么多东西了!我们使用 ReadAt 特征 在第 3 部分中,我认为很高兴看到其中的差异。
然后 cargo run 将打印 /etc/hosts 的内容(作为文本)。 当然,我们也可以运行 cargo build 并获得编译后的可执行文件 在target/debug/readfile中。
酷熊的热心小贴士
<Rust 编程语言>是对这门语言的简单介绍。
如果您想休息一下来浏览一下,可以免费在线获取前几章,酷熊不会怪你的。
为了我们这些Rust新手的利益,我将逐一介绍 部分并解释它的作用。 (如果代码对您来说很明显,请随意跳至下一节)
这是一个主函数 - 它是程序启动时运行的函数:
Rust code
1 |
|
由于我们要执行可能失败的操作,例如读取文件, 我们可以使用返回结果的 main 形式。
Rust code
1 |
|
Result 是一个泛型类型,T 是……结果的类型(如果一切顺利的话)。 如果出现问题,E 是错误的类型。
在我们的例子中,我们并没有真正得到结果,因此对于 T 我们可以只使用 空元组,()。至于错误类型,E,唯一容易出错的操作是 I/O(输入-输出),因此我们可以使用std::io::Error。
Rust code
1 |
|
接下来,我们注意到,与我们的 node.js 示例不同,这里我们必须打开 a 在read之前先将其open。
Rust code
1 |
|
按照目前的情况,该程序打开该文件,但不对其执行任何操作。 (事实上,编译器会警告我们这一点)。
std::fs::File 实现的 std::io::Read 特征中定义了一个 read_to_string 方法,听起来和我们想要的的一模一样:
- 我们需要use该特征,以便我们可以使用它的方法。
- 我们需要一个可以读取文件的字符串。
注意:
- 字符串必须是可变的,因为我们正在更改它(通过将文件的内容写入其中)。
- 文件还必须是可变的,因为从中读取的内容会改变文件中的位置 - 这是可变的,但是不是文件本身可变,而是文件的句柄(handle)。
最后,我们可以使用println宏来打印它。由于它是一个宏, 我们需要在它的名字后面写一个感叹号来调用它。
Rust code
// import everything we need
1 |
|
希望这足够清楚,即使对于那些不熟悉 Rust 的人来说也是如此。
我们学到了什么?
在Rust中,我们必须首先创建一个新的字符串,以接收文件的内容。
打开文件和读取文件都是可能失败的操作。
任何变更都必须通过 mut 关键字明确允许。从一个读取文件是一个可变的,因为它改变了我们在文件中的位置。
用C读取文件
C标准库为我们提供了“高级”的库。界面打开 并读取文件,所以让我们尝试一下。
C code
1 |
|
好吧,这很痛苦,让我们回顾一下:首先我们需要打开文件。自从 这是一个“高级”的API,我们可以通过字符串常量指定模式。 我们只对阅读感兴趣。
C code
1 | FILE *file = fopen("/etc/hosts", "r"); |
然后,我们必须进行一些错误检查。请注意,我们不会 能够告诉为什么我们无法打开该文件,只是它不起作用。 我们必须调用更多函数才能做到这一点。
C code
1 | if (!file) { |
然后,就像在 Rust 中一样,我们必须分配一个缓冲区。注意,这里不保证说此时它是一个字符串 - 它只是一个存储字节的地方。我任意选择“16字节”这样它就足够短,我们会注意到我们的阅读逻辑是错误的(希望如此)。
C code
1 | const size_t buffer_size = 16; |
然后,我们只是尝试重复读取一个缓冲区,直到达到 错误或文件结尾。同样,正确的错误处理需要 更多代码和更多函数调用。
Rust 免费为我们提供了这一切。只是说一下。
C code
1 | while (true) { |
哦,C 语言中另一个有趣的地方。没有字符串类型。但这没关系,因为 printf 的 %s 格式化程序一旦遇到 null 就会停止 字节。只要我们永远不会忘记设置它,并且永远不会忽略错误(怎么会有人犯这种错误?)那么我们绝对不会暴露敏感信息信息或允许远程代码执行。这里没什么可看的。

最后,我们确保打印最后的换行符,因为这就是行为良好的 CLI(命令行界面)应用程序可以做到这一点。我们return了0,因为显然对于C来说0代表成功(除非它不是,并且这意味着错误 - 这要看情况)。
我们学到了什么?
在C中,没有字符串,只有“数组”。字节数。使用stdio时,我们必须 手动分配一个缓冲区来读取文件。如果缓冲区不是 足够大,我们就得反复读进去。
返回的 FILE* 是一个不透明结构体,引用打开的 文件。我们只能将它与其他 stdio 函数一起使用,永远不要查看内部。fopen
C 很容易搬起石头砸自己的爪子:因为一个错误挂掉,忘记以空字节 (\0) 终止字符串,忘记检查返回值或错误地测试它们。
酷熊的热心小贴士
学习C很重要,因为很多项目都是用它写的。
但如今,通常有更好的替代方案。
不使用stdio的情况下使用 C 读取文件
上面的API这仍然太高级了。 fopen、fclose、fread、fwrite 函数族为我们做了很多事情。例如,他们进行缓冲。
所以如果你运行这个程序:
C code
1 |
|
然后它什么也不打印:
1 | $ gcc -O3 --std=c99 -Wall -Wpedantic woops.c -o woops |
因为这些点实际上直到换行符出现也没被打印。它们只是存储在内存缓冲区中。但是程序崩溃了,因此退出处理程序无法运行,所以没有任何内容写入终端。
酷熊的热心小贴士
这行:
C code
*((char*) 0xBADBADBAD) = 43;
...导致分段错误因为我们正在写入的内存是 几乎肯定在我们进程的地址空间中无效。
但是,我们不能指望这种情况总会发生。在一些嵌入 系统,这将是 默默地破坏数据或什么也不做。
但是!如果我们使用 open、read、write、close,现在我们就开始使用低级API。这个程序:
C code
1 |
|
…产生预期的输出:
1 |
|
酷熊的热心小贴士
-O3 是第三级优化。 -Wall 表示“所有警告”。 -Wpedantic 相当于要求被烘烤的编译器。
那么,我们可以更新我们的 readfile 程序以使用文件描述符吗 <stdio.h>?绝对!
C code
1 |
|
哇哦,是的,现在这太冗长了,我们现在肯定是真正的程序员了。
我们学到了什么?
stdio 是一个“高级”接口。出于性能考虑,处理缓冲的文件接口。
open()、read() 和 write() 函数属于较低级别。使用这些时, 我们应该自带缓冲!
一点自省
还记得我们使用cat打印/etc/hosts的内容吗?
天啊,那时我们还年轻。
嗯,cat 几乎随每个 Unix-like 系统一起提供,他们肯定是真正的程序员写的。如果有办法了解他们的秘密就好了。
事实证明,strace正是我们要的。
Shell session
1 |
|
strace 是做什么的?它“跟踪系统调用和信号”。稍后会详细介绍。 此时,我们所知道的是它打印了很多行,而我们不知道 关心他们所有人。
我们只想知道cat如何读取文件!答案就在附近某处 跟踪结束:
1 |
|
嘿,这很熟悉!让我们与 readfile 二进制文件的 strace 进行比较。 (C 语言使用 open、read 和 write)。
1 |
|
所以,看起来,最终,readfile 和 cat 做了同样的事情,除了 cat:
使用fstat系统调用来找出文件的大小,
分配适当大小的缓冲区
在一个系统调用中读取整个文件
还在一个系统调用中写入整个文件
我们学到了什么?
strace 工具使我们能够了解程序的底层功能。并非所有内容都会显示在 strace 跟踪中,但很多有趣的东西都会显示。
酷熊的热心小贴士
cat 命令的名称来自“catenate”,是“concatenate”的同义词。
更新我们的心理模型
现在,看起来有很多一堆读取文件的方法。取决于 根据您使用的语言 - C 甚至为您提供了两种开箱即用的方法!
我们现在的心理模型可能是这样的:

…但我们可以很容易地反驳这一点。
如果我们跟踪第一个程序(node.js),我们会发现:
Shell session
1 | $ strace node ./readfile.js |
就像其他一样,它使用 open 和 read!而不是 fstat, 它使用 statx,返回 扩展文件状态。
酷熊的热心小贴士
“状态”是指文件的大小是以字节为单位的,它属于哪个用户和组 各种时间戳和其他较低级别的信息,我们将得到 到以后。
同样,如果我们追踪 Rust 的情况,我们会发现:
Shell session
1 |
|
它还使用open和read。
因此,无论我们使用什么语言,我们总是会回到openat, read、write。
让我们更新我们的思维模型:

我们学到了什么?
Node.js、Rust 和 C 应用程序最终都使用相同的几个函数: open()、read()、write()等
你做到了!
哇,有很多内容要讲。但你还是坚持到了最后!
我们正在快速浏览大量材料。不完全也没关系 了解一切。其中许多主题可能会更深入地涵盖 在某些时候在单独的文章中。
如果第 1 部分没有教给您太多内容,也没关系!有时候提醒是件好事。 接下来的部分确实要低得多。我确信你身上有某些东西 不知道。