编码
Java8及之前的String保存的方法是这样的:
1 | public final class String |
注释中这样描述:
A String represents a string in the UTF-16 format in which supplementary characters are represented by surrogate pairs (see the section Unicode Character Representations in the Character class for more information). Index values refer to char code units, so a supplementary character uses two positions in a String。
即Java使用UTF16编码构建String,对于扩展字符,String将使用2个char这非常好验证:
1 | public static void main(String[] args) { |
上例可知,对于想要获取字符串长度的场景,如果存在扩展字符的情况下我们使用length(),将得到错误的结果。想要得到正确的结果应使用codePoint().count(),这个方法将是o(n)复杂度了。对于需要估算String占用空间的场合来说,length似乎没什么问题,但是对于需要真正计算字符个数的情况,比如造个富文本框的轮子时,length将导致问题。
同理还有charAt也不能得到正确的结果 :
1 | String b = "🐎q🐎"; |
那codePointAt可以随机访问吗,从注释来看这里返回的是unicode单元?
1 | System.out.println((char) b.codePointAt(1)); |
从字符来看q是第二个字符,但是用1访问是?,我们访问第三个字符,用2访问才是q。总之在存在扩展字符的情况下,我们无法在不遍历的前提下定位到自己需要的字符,无法在 o(1) 复杂度下随机访问字符。
当然,新型的语言大多用utf8存储字符串了(Go,Rust),Java,C#,python(3.3之前)的做法固然有一些历史局限性和妥协,尤其是在ascii为主的字符串场景下,utf16存储效率还是太低了。很多较老的实现倾向于以牺牲空间和一定程度上扩展字符的兼容性来换取高速随机访问字符。不过在以ascii为主的web大行其道的当下,以及越来越多的语言字符,以及emoji加入双字节Unicode越来越难以满足兼容性需求,人们才会倾向于选择utf8为默认字符串实现
所以,java9String改为这样:
1 |
|
java9确实改用byte数组保存字符串了。
代码中这个地方将标记此字符串的编码方式
1 | private final byte coder; |
coder可以取值为LATIN1(0)和UTF16(1),Latin1每个字符占用一个字节,debug可以看到 :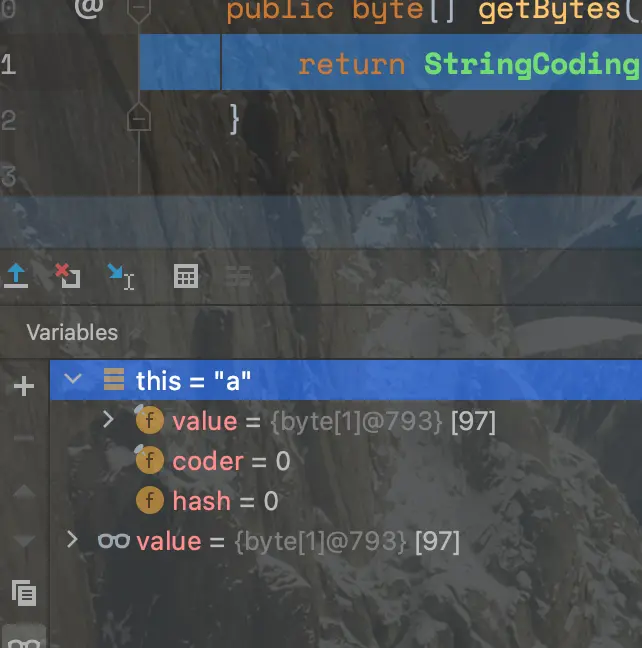
非ascii字符仍将使用UTF16编码
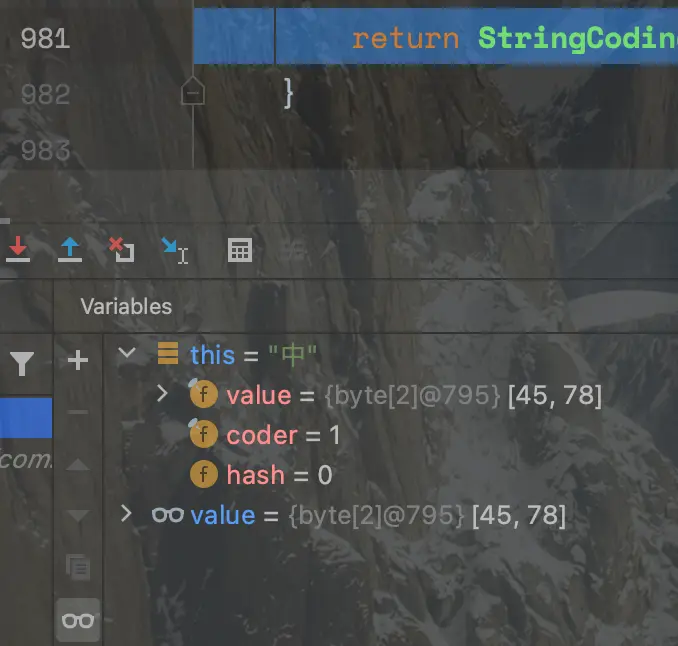
那么调用toChar这个api时如果是latin1编码就需要将其膨胀为2字节。如果是UTF16则需要将相邻byte高低位合并为char。
对于ascii字符为主的应用,加入字符串压缩确实可以节约不少内存,但是也会引入一定的cpu损耗,用户这里可以权衡一下。
创建String时会根据配置 -XX:-CompactStrings 决定是否开启字符串压缩。
String的编码更多的是考虑内存占用,访问效率等因素下做出的权衡。在传输,持久化的场景下就是另一回事了,事实上在这些场景上,大多数开发者会选择UTF-8,这些场景下随机访问不再是用户考虑的因素,占用空间,兼容性将是考虑的重点。关于UTF8和UTF16的争论,这里有个关于utf8的有趣的宣言 http://utf8everywhere.org/zh-cn
内存
那么String保存在哪里呢?
1 | System.out.println(System.identityHashCode("aa")); |
嗯,我们初步观察上面的实验结果:
“aa” 这个字符串不管在代码中声明多少次都指向了同一字符串对象。
new String(“aa”) 可以生成一个新的String对象,但是这个对象继承原String所有的参数,所有新老String的hashCode相同,equals方法也会返回true,但是如果用==比较的话,实际比较的是两个对象的oop指针,所以==是返回false的。
但是intern方法会穿透你套的这层对象,取出底层的字符串对象,而且套多少层都能正确取出。
实际上JVM内部会维护常量池,大概是这样的关系
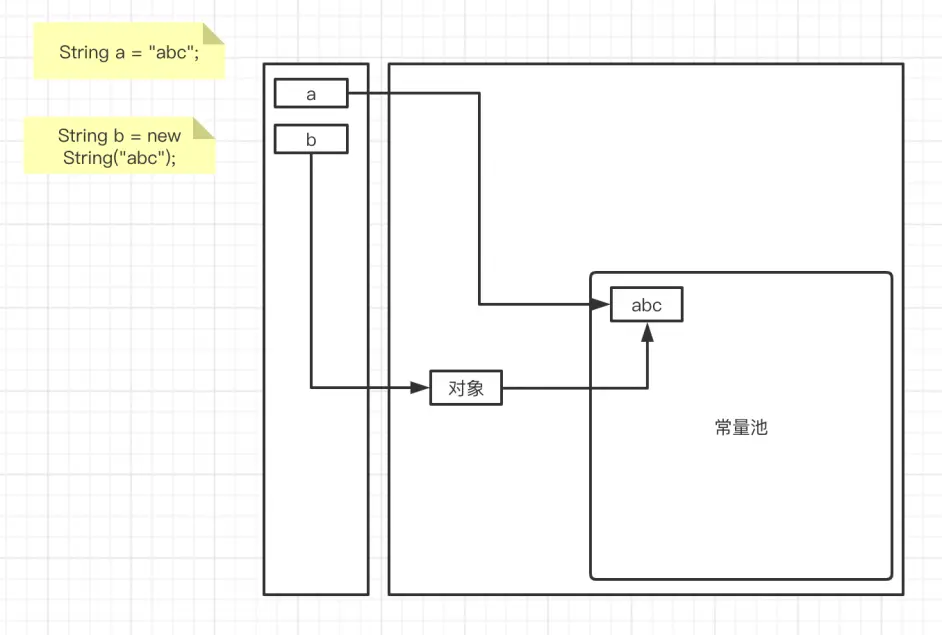
intern 则是直接从常量池取String对象 Java8 HostSpot中流程如下
1 | oop StringTable::intern(Handle string_or_null, jchar* name, |
String常量池是Hash表加链表。在代码中通过ldc这个指令生成的字符串会尝试写入常量池,所以在代码中反复用ldc指令声明同一个字符串会指向同一个对象,这样能最大程度的节约内存空间。而对于运行时生成的字符串,用户使用byte数组和相应编码生成的对象则完全在堆里,将随着gc被释放。
那啥时应该用intern呢?当你非常明确某段高频执行的代码会反复产生String对象却指向相同的常量池对象时:比如某些序列化,日志框架的实现。
“+” 应该怎么用?
Java程序员经常被告知的一条优化就是,不要在密集循环中使用+号拼接字符串。实际上 + 拼接是Javac会进行脱糖,每次使用+号会产生一个全新的StringBuilder对象,编译器无法替用户将StringBuilder提到循环外,用户手动创建StringBuilder在循环中append效率会高很多。