在web开发中,一些复杂的高负载的中间件常常需要追踪数万个链接。我们应该如何高效地追踪这些链接,并管理他们的超时呢?
https://blog.acolyer.org/2015/11/23/hashed-and-hierarchical-timing-wheels/
这篇论文介绍了一些管理计时器的方法。首先对我们的计时器建模:计时器共需满足4个操作
- 启动定时器,指定定时器在多久会触发,指定相关回调。
- 停止定时器
- 我们的定时器能够 按照时间最小粒度回调 tick
- 回调时间到了能够触发相应回调。
我们先看一些方案
无序计时器列表
将所有计时器都无脑塞到同一列表,每次tick触发都必须遍历完整列表,将每个计时器都减少tick时长。如果遇到减少到0,则调用回调并将计时器删除。启动计时器的时间复杂度是O(1),停止(删除)计时器的复杂度是O(1)每次tick检查回调的复杂度则是O(n)。有序计时器列表
这里将离到期最近的放在列表头,按照时间近远排序,如果我们的实现是链表,我们的tick将是O(1)复杂度,启动是O(n),停止是O(1)。如果我们使用数组+ringbuffer实现,则tick是O(1),启动是O(lgn),停止是O(1) ,但是会带来数组扩容时O(n)复制损耗。定时器树
将定时器改为树状结构存储,比如红黑树,可以保证我们的启停,tick都是O(lgn)。简单的时间轮
如果计时器最大计时比较小,那么一个环上n个槽,每个槽都是最小时间单位,每次tick移动一位并执行回调,此时启动,停止,tick都是O(1)。带有有序定时器列表的哈希轮
如果需要计时的周期较长,简单时间轮会消耗大量内存。我们一个可行的优化方案是使用一哈希时间轮,我们将计时器同合理的轮长度取模,并在时间轮上标记其时间。如果哈希冲突后将计时器按照顺序放到槽位的链表中。最好的情况下,启动,停止都是O(1)最坏是O(n)明显哈希冲突,tick则是bucket数 ,常量级。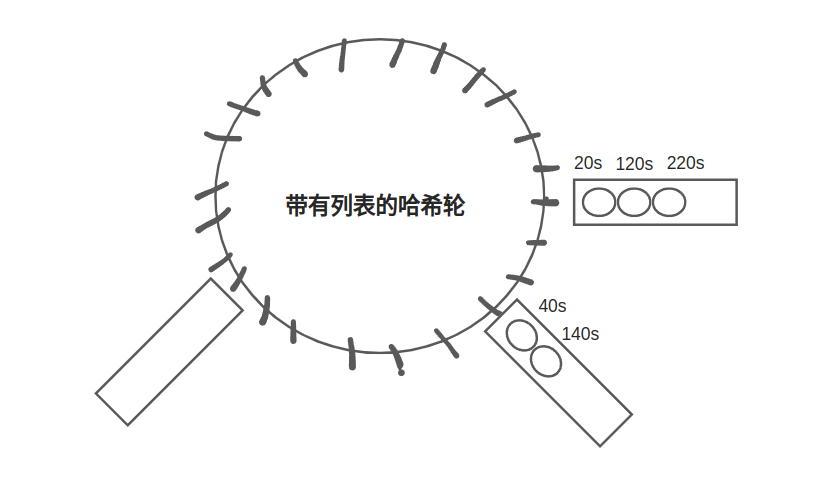
方案5的优化
由于方案5存的是绝对时间没有存具体需要转几轮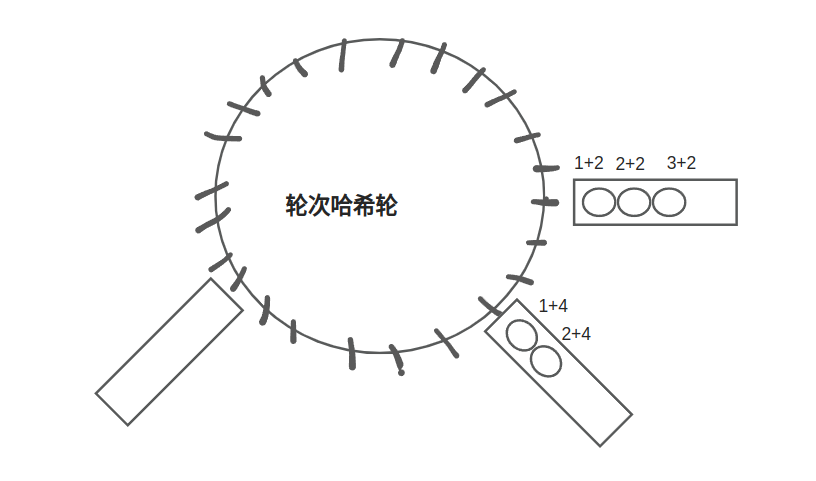 所以可以做这样的优化,避免无谓的轮转。
所以可以做这样的优化,避免无谓的轮转。
需计算轮数 c = j / num-buckets_ 和 每轮增量 s = j % num-buckets。
启动一个计时器现在有最坏情况和平均情况 O(1),并且每次记账的最坏情况为 O(n),但平均为 O(1)。
7.分层时间轮
另一种处理由简单计时轮方法引起的内存问题的方法是在层次结构中使用多个计时轮。假设我们要存储具有第二粒度的计时器,可以将其设置为未来最多 100 天。我们可以构造四个轮子:
● 有 100个槽的日轮
● 带 24 个槽的时轮
● 带 60 个槽的分钟轮
● 带 60 个槽的秒轮
这总共有 244 个槽,用于处理总共 864 万个可能的定时器值。每次我们在一个轮子上转一整圈,我们就会将下一个最大的轮子前进一个槽(论文描述了分钟、小时和星期滴答时钟的轻微变化,但效果是相同的)。
时间轮的实现
前面我们聊完了大量定时器如何高效的存储和访问,后面我们要看看一些常见的语言和运行时在这个问题上是如何实现和取舍的。
JDK - Timer
Timer 属于 JDK 比较早期版本的实现,它可以实现固定周期的任务,以及延迟任务。Timer 会起动一个异步线程去执行到期的任务,任务可以只被调度执行一次,也可以周期性反复执行多次。我们先来看下 Timer 是如何使用的,示例代码如下。
1 | Timer timer = new Timer(); |
可以看出,任务是由 TimerTask 类实现,TimerTask 是实现了 Runnable 接口的抽象类,Timer 负责调度和执行 TimerTask。接下来我们看下 Timer 的内部构造。
1 |
|
TaskQueue 是小根堆,deadline 最近的任务位于堆顶,queue[1] 始终是最优先被执行的任务。所以使用小根堆的数据结构,启动时间复杂度 O(1),新增 Schedule 和取消 Cancel 操作的时间复杂度都是 O(logn)。
Timer 内部启动了一个 TimerThread 异步线程,不论有多少任务被加入数组,始终都是由 TimerThread 负责处理。TimerThread 会定时轮询 TaskQueue 中的任务,如果堆顶的任务的 deadline 已到,那么执行任务;如果是周期性任务,执行完成后重新计算下一次任务的 deadline,并再次放入小根堆;如果是单次执行的任务,执行结束后会从 TaskQueue 中删除。
JDK - ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor是Java中的一个线程池,可以用来执行定时任务或周期性任务。它是ThreadPoolExecutor的子类,继承了ThreadPoolExecutor的大部分特性,并添加了定时执行任务的功能。
异步
在一些异步体系中,比如java的netty或者rust的tokio,为了避免使用标准库实现时间轮
阻塞掉异步运行时,这些异步体系都会自己实现时间轮算法。
Netty HashedWheelTimer
基本数据结构
1 | public class HashedWheelTimer implements Timer { |
这里netty的实现是我们前面提到的第六种,hash + 双向链表。
1 | public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) { |
构造函数
1 |
|
- threadFactory,线程池,但是只创建了一个线程;
- tickDuration,时针每次 tick 的时间,相当于时针间隔多久走到下一个 slot;
- unit,表示 tickDuration 的时间单位;
- ticksPerWheel,时间轮上一共有多少个 slot,默认 512 个。分配的 slot 越多,占用的内存空间就越大;
- leakDetection,是否开启内存泄漏检测;
- maxPendingTimeouts,最大允许等待任务数。
有趣的是netty为了降低冲突,新建的任务并不会直接入bucket。
1 | private final Queue<HashedWheelTimeout> timeouts; |
而是放入一个队列中
在worker启动时,一次从队列中取一大批任务自己慢慢执行。
1 | private void transferTimeoutsToBuckets() { |
tokio-timer
0.2采用了分层时间轮算法
https://tokio.rs/blog/2018-03-timers
1 |
|
这里Stack是一个双向链表组成的栈。
Go
Golang默认全异步,目前Golang的运行时将网络轮询和计时器二和一深捆绑度了,但是运行时计时器并不能为了节约空间牺牲精度,所以不会采用时间轮算法。
- Go 1.9 版本之前,所有的计时器由全局唯一的四叉堆维护1;
- Go 1.10 ~ 1.13,全局使用 64 个四叉堆维护全部的计时器,每个处理器(P)创建的计时器会由对应的四叉堆维护2;
- Go 1.14 版本之后,每个处理器单独管理计时器并通过网络轮询器触发;